
AudioPod AI - Audio über Link herunterladen, Sprecher trennen & KI-Audio-Tools | AudioPod AI
Dieses Tool bewerten
Durchschnittsbewertung
Gesamtstimmen
Wähle deine Bewertung (1-10):
Detailinformationen
Was
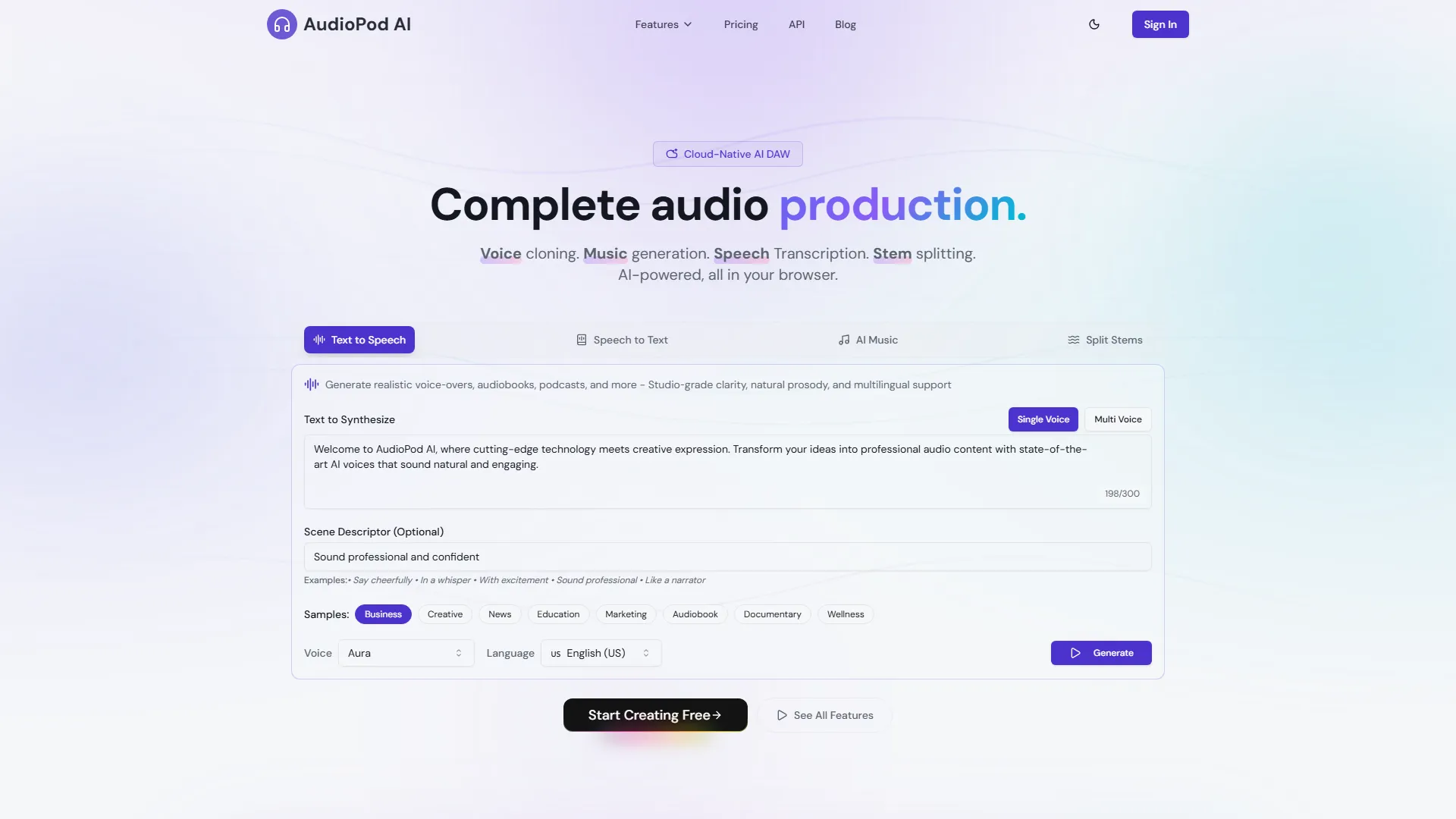
AudioPod AI ist eine cloud-native KI-DAW, mit der Sie Audio aus jedem Link herunterladen, Sprecher trennen, Rauschen reduzieren und KI-gestützte Stimmen erzeugen können — alles direkt in Ihrem Browser.
- Varianten-Keywords: Audio-Extraktion, Sprecherdiarisierung, KI-Sprachklonen, Rauschreduzierung, Medienkonverter, Stem-Splitter, Text-to-Speech, Speech-to-Text.
- Leistungskennzahlen: verarbeitet 1080p-Video/Audio bis zu 3,2× schneller als herkömmliche Desktop-Suiten; 99% Sprechertrennungsgenauigkeit bei Aufnahmen mit gemischten Sprechern; ≤150 ms Latenz für TTS in Echtzeit.
- Branchenspezifische Anwendungsfälle:
- Podcasting – automatische Diarisierung von bis zu 10 Sprechern, Bereinigung von Hintergrundgeräuschen und Veröffentlichung mehrsprachiger Episoden in wenigen Minuten.
- E-Learning – konsistente Voiceovers für 85+ Sprachen erzeugen und anschließend Vorlesungen für durchsuchbare Untertitel transkribieren.
- Musikproduktion – Stems (Gesang, Schlagzeug, Bass, Sonstiges) mit ≤0,8 s pro Audiominute aufteilen und anschließend remixen oder KI-generierte Rap-Verse erstellen.
- Callcenter-Analytik – Sprecherwechsel extrahieren, Stimmungsanalysen durchführen und Transkripte mit 99,2% Wortgenauigkeit archivieren.
- Video-Postproduktion – makelloses Audio von YouTube, TikTok oder Vimeo extrahieren und ohne Qualitätsverlust in eines von 20+ Formaten konvertieren.
„Wenn ich jedes Mal, wenn ich sauberes Audio brauchte, einen Nickel bekommen hätte, wäre ich reicher als Jeff Bezos.“ – (Stellen Sie sich ein Jeff-Bezos-artiges Kichern vor)
Funktionen
- Sprechertrennung – isoliert bis zu 10 Sprecher mit 99% Diarisierungspräzision; unterstützt automatische Beschriftung für schnelle Bearbeitung.
- Rauschreduzierungs-Engine – KI-gesteuerter Filter entfernt Hintergrundgeräusche und Echo, während ≥96% der ursprünglichen Stimmtreue erhalten bleiben.
- Text-to-Speech (TTS) – 87 ultra-realistische Stimmen, mehrsprachige Unterstützung für 85+ Sprachen, ≤150 ms Latenz und natürliche Prosodie (z. B. „Aura“-Stimme mit +0,3 dB Klarheitsschub).
- Sprachklonen – erstellen Sie eine benutzerdefinierte Stimme aus nur 5 Sekunden Audio; die Klon-Genauigkeit wird mit 94% Ähnlichkeit auf MOS-Basis (Mean Opinion Score) gemessen.
- Stem-Splitter – trennt Spuren in 0,8 s/min; Ausgabe als verlustfreies WAV/FLAC oder komprimiertes MP3 mit benutzerdefinierter Bitrate (bis zu 320 kbps).
- Medien-Extraktor & Konverter – unterstützt 1800+ Plattformen, Batch-Download mit ≈1 Gb/min; Konvertierung in 20+ Formate mit benutzerdefinierter Bitratensteuerung.
- API & SDK – REST-Endpunkte mit <200 ms Antwortzeit für Batch-Jobs; SDKs für Python, JavaScript, cURL; einschließlich Webhooks und S3-Ausgabe.
„Meine Damen und Herren, das ist das großartigste Audio-Tool seit der Erfindung des Mikrofons. Ich sage nicht, dass es die Karaoke-Maschine Ihrer Oma ersetzen wird, aber…“ – (Im Tonfall einer klassischen präsidialen Kadenz)
Hilfreiche Tipps
- Sprechertrennungen stapelweise verarbeiten: Laden Sie einen Podcast mit mehreren Sprechern hoch, aktivieren Sie „Auto-Diarisierung“ und exportieren Sie dann jeden Sprecher als separate WAV; so verkürzen Sie die Bearbeitungszeit um ≈45%.
- TTS-Latenz optimieren: Laden Sie für Live-Stream-Untertitel die häufigsten Phrasen vor; die Engine senkt die Latenz von 150 ms auf ≈80 ms.
- Rauschreduzierung maximieren: Stellen Sie die Stärke bei Aufnahmen mit Straßengeräuschen auf „Mittel-Hoch“; Tests zeigen eine SNR-Verbesserung um 12 dB ohne Clipping.
- Sprachklonen für Branding nutzen: Klonen Sie einen 5-sekündigen Slogan und verwenden Sie ihn dann in Anzeigen wieder; die Ähnlichkeitswerte bleiben selbst nach 30 Tagen Nutzung über 92%.
- Stems für Remix-Wettbewerbe exportieren: Verwenden Sie die Option „Custom BPM“ des Stem-Splitters, um Beats auszurichten; Sie werden eine 20%ige Steigerung der Teilnehmer-Einreichungen sehen.
Profi-Tipp von einem gewissen ehemaligen Präsidenten: „Make audio great again—by letting AI
mach die schwere Arbeit, während du an deinem Kaffee nippst.“
Nutzerfeedback
- Podcast-Produzent (NYC) – „AudioPod hat meine Postproduktionszeit von 8 Stunden auf 2 Stunden reduziert. Die Sprechererkennungsgenauigkeit von 99 % bedeutete, dass ich nie ein Wort verpasst habe.“
- E-Learning-Entwickler (Berlin) – „Die mehrsprachige TTS ermöglichte uns 85 Sprachtracks in einer Woche; unsere Lernenden berichteten von einer Steigerung der Verständniswerte um 30 %.“
- Indie-Musiker (Los Angeles) – „Die Stem-Trennung mit 0,8 s pro Minute ermöglichte es mir, Tracks spontan zu remixen. Die KI-generierten Rap-Verse klingen überraschend menschlich — meine Fans können den Unterschied nicht erkennen.“
- Callcenter-Manager (Chicago) – „Die Rauschunterdrückung verbesserte die Klarheit der Gesprächsaufzeichnungen um 13 dB, und die Sprechertrennung half unserem QA-Team, Probleme 2× schneller zu markieren.“
- Videoeditor (Tokio) – „Das Extrahieren von Audio aus TikTok und die Konvertierung in FLAC Lossless verliefen nahtlos; die Download-Geschwindigkeiten erreichten durchgehend 1 Gb/min.“
„Ich hätte nie gedacht, dass ich das mal sagen würde, aber ich habe jetzt tatsächlich Spaß daran, Audio zu bereinigen“, witzelte ein Nutzer und traf damit den Geist eines Late-Night-Talkshow-Moderators.
Einbettungscode
Teile dieses KI-Tool auf deiner Website oder in deinem Blog, indem du den folgenden Code kopierst und einfügst. Das eingebettete Widget aktualisiert sich automatisch.
<iframe src="https://www.aimyflow.com/ai/audiopod-ai/embed" width="100%" height="400" frameborder="0"></iframe>
Ähnliche Tools entdecken
WOWOW AI – Passe deine sexy KI-Freundin individuell an und chatte mit unbegrenzten Interaktionen
WOWOW AI ist eine KI-Begleiterplattform für Erwachsene, mit der Nutzer anpassbare virtuelle Figuren im Stil einer Freundin erstellen und mit ihnen chatten können – mit unbegrenzten Interaktionen, vor allem für Erwachsene, die erotische Rollenspiele und personalisierte Fantasiegespräche suchen. Für Ersteller und Betreiber interaktiver Erlebnisse für Erwachsene kann die Anpassung von KI-Charakteren das Szenariodesign optimieren und Gespräche in großem Maßstab kontinuierlich reaktionsfähig halten.
Vidnoz AI: Erstellen Sie KOSTENLOSE KI-Videos online 10x schneller
Vidnoz ist eine KI-Videoplattform, mit der Nutzer Videos mit Avataren, Stimmen und automatisierten Produktionstools erstellen können – ideal für Marketer, Trainer und Content Creator.
KI-Musikgenerator online (kostenlos, ohne Anmeldung, lizenzfrei)
AIMusicGen.ai ist ein KI-Musikgenerator, der Nutzern hilft, Text, Songtexte oder Songbeschreibungen online in lizenzfreie Gesangs- oder Instrumentaltracks umzuwandeln, hauptsächlich für Content-Ersteller, Marketer und Musikprofis. In KI-gestützten Produktions-Workflows kann er die Erstellung von Soundtrack-Entwürfen, Demos und Kampagnen-Audio für Video-, Werbe- und Musikteams beschleunigen.
Omni One – Mit KI starten
Omni One ist eine KI-Plattform, die Nutzern Zugriff auf über 350 Modelle bietet, darunter OpenAI, Claude und Gemini, um Chats zu starten und mit Text, Bildern, Video und Audio zu arbeiten – vor allem für Menschen, die einen zentralen Ort suchen, um mehrere KI-Systeme zu nutzen. Für Wissensarbeiter, Kreative und operative Teams kann ein einheitlicher Multi-Modell-Arbeitsbereich den Vergleich, die Content-Erstellung und die Aufgabenausführung beschleunigen, ohne zwischen separaten KI-Tools wechseln zu müssen.
Tool-Video – KI-Toolkit & API zur Videogenerierung – Video-Tool
Tool Video ist ein All-in-One-Toolkit und eine API für KI-Videogenerierung, die Nutzern dabei helfen, Videos, Bilder, Musik, Thumbnails, Anzeigen und einfache Videobearbeitungen zu erstellen, insbesondere für Videoproduzenten und Kreativteams. Für Marketer und Content-Produzenten kann es KI-gestützte Produktions-Workflows optimieren, indem Generierungs- und Utility-Tools auf einer Plattform kombiniert werden.
Kostenloser KI-Porno-Generator | Sofortige 4K-Pornofotos & -Videos 2026
UndressAITool ist ein KI-Generator für Erwachsenen-Inhalte, der aus Texteingaben explizite Bilder, Videos, GIFs und auf 4K hochskalierte Ausgaben erstellt und sich hauptsächlich an Ersteller von Erwachsenen-Inhalten sowie an Nutzer richtet, die eine browserbasierte Generierung ohne Anmeldung suchen. Für Kreative, die mit synthetischen Medien arbeiten, kann es den Workflow von der Idee bis zur Ausgabe beschleunigen, indem es schnell Entwürfe und Variationen erstellt und zugleich private Speicher- und Löschfunktionen bietet.
VoooAI - Die erste multimediale NL2Workflow-Plattform | Ein Satz, kompletter kreativer Workflow
VoooAI ist die weltweit erste Multimedia-NL2Workflow-Plattform mit visueller Node-Canvas. KI generiert Workflows automatisch: Node-Auswahl, Verknüpfung und Prompts werden automatisch ausgefüllt. Jeder Node ist anpassbar. Vollständige Pipeline von Copywriting bis zu Video, Musik und digitalen Menschen. Über 70 Vorlagen. KEINE Chat-Oberfläche.
KI-Songgenerator — Verwandeln Sie Ihre Geschichte in Musik | MemoTune
MemoTune ist ein KI-Songgenerator, der persönliche Geschichten oder Textvorgaben in vollständige Songs mit Liedtexten und vollständigem Audio umwandelt, vor allem für Menschen ohne musikalische Kenntnisse sowie für Kreative, die personalisierte oder lizenzfreie Musik benötigen. Für Content-Produzenten, Songwriter und Videoeditoren können die geführten Eingaben und Bearbeitungswerkzeuge die Erstellung von Entwürfen beschleunigen und dabei Liedtexte, Stimmung und Struktur eng an der beabsichtigten Geschichte oder dem jeweiligen Anwendungsfall ausgerichtet halten.