
Evidently AI - Plattform für KI-Evaluierung & LLM-Observability
Dieses Tool bewerten
Durchschnittsbewertung
Gesamtstimmen
Wähle deine Bewertung (1-10):
Detailinformationen
Was
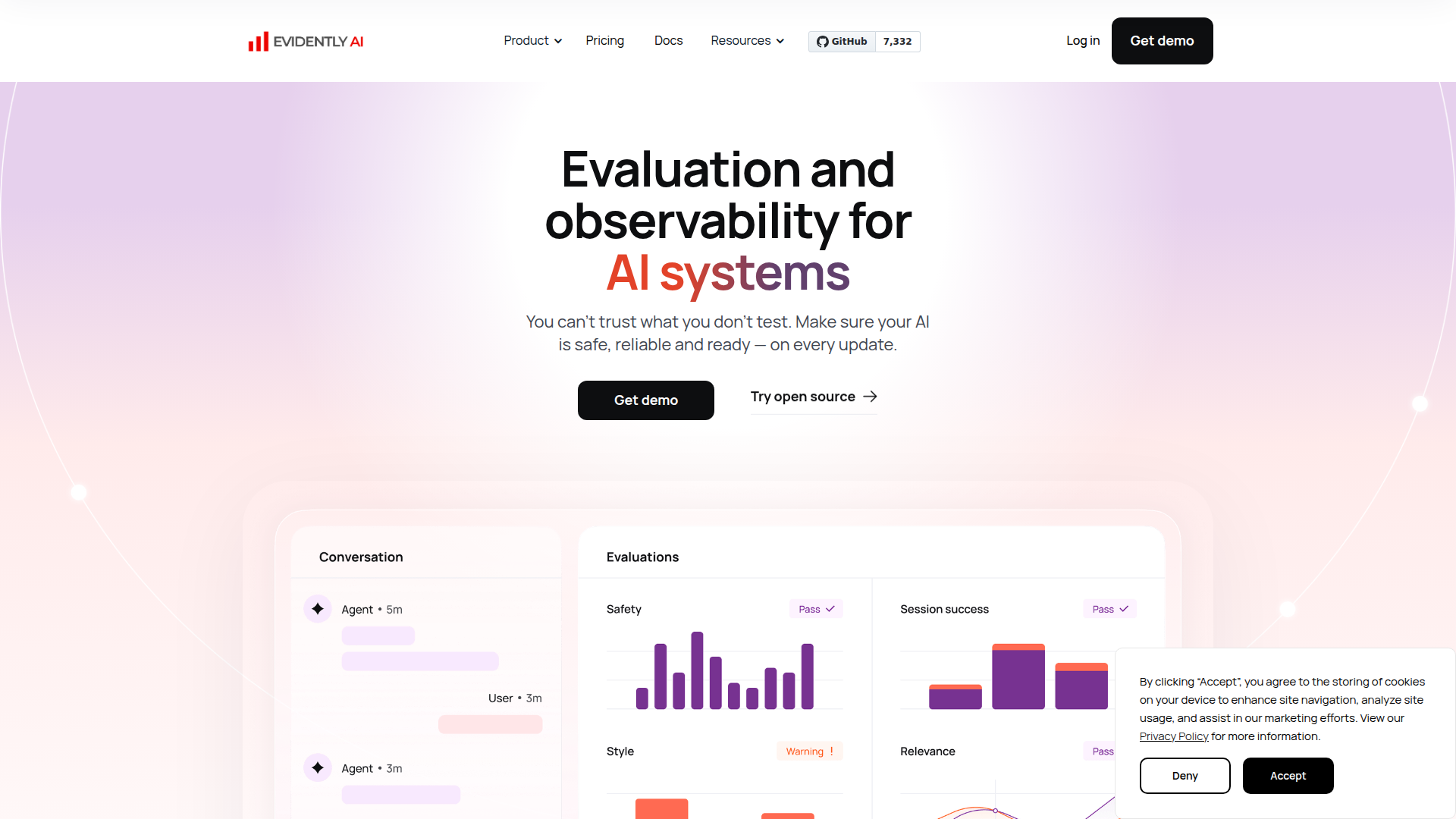
Evidently AI ist eine KI-Bewertungs- und Observability-Plattform für Teams, die LLM-Anwendungen, KI-Agenten, RAG-Systeme und traditionelle ML-Produkte entwickeln. Sie wurde entwickelt, um KI-Entwicklern dabei zu helfen, Qualität, Sicherheit, Retrieval-Leistung und Modellverhalten vor und nach Updates zu testen.
Das Produkt scheint sowohl als kommerzielle Plattform als auch als Open-Source-orientiertes Tooling-Ökosystem positioniert zu sein, das auf der Evidently-Python-Bibliothek aufbaut. Der Kern-Workflow umfasst die Generierung von Testfällen, die Durchführung automatisierter Bewertungen mit integrierten oder benutzerdefinierten Metriken sowie die kontinuierliche Nachverfolgung der Leistung über Dashboards und Berichte, um Regressionen, Drift und neu entstehende Risiken zu erkennen.
Funktionen
- Automatisierte KI-Bewertung — Misst Ausgabegenauigkeit, Sicherheit und Qualität und macht Fehlerpunkte auf Antwortebene in teilbaren Berichten sichtbar.
- Synthetische und adversariale Testgenerierung — Erstellt realistische Edge-Case- und angriffsähnliche Eingaben, die auf einen bestimmten Anwendungsfall zugeschnitten sind, und hilft Teams so, Fehlermodi vor der Bereitstellung zu untersuchen.
- Kontinuierliches Testen und Observability — Verfolgt das Systemverhalten über Modell- oder Prompt-Updates hinweg, sodass Teams Drift, Regressionen und neue Risiken im Zeitverlauf erkennen können.
- 100+ integrierte Metriken mit Unterstützung für benutzerdefinierte Bewertungen — Ermöglicht Teams, Regeln, Klassifikatoren und LLM-basierte Bewerter zu kombinieren, um ein Qualitätssystem zu definieren, das zu ihrer Anwendung passt.
- RAG-spezifische Bewertung — Testet Retrieval-Qualität, Kontextrelevanz und Halluzinationsverhalten, um fundierte Antworten in retrievalbasierten Systemen zu verbessern.
- Tests für KI-Agenten und prädiktive Systeme — Erweitert die Bewertung über einzelne LLM-Ausgaben hinaus auf mehrstufige Workflows, Tool-Nutzung, Klassifikatoren, Zusammenfasser, Empfehlungssysteme und andere ML-Modelle.
Hilfreiche Tipps
- Definieren Sie Bewertungskriterien zuerst nach Fehlermodi — Bei Produkten wie diesem ist es in der Regel effektiver, Tests nach Halluzinationen, PII-Leaks, unsicheren Ausgaben und Workflow-Zusammenbrüchen zu strukturieren als nach generischen Modellbewertungen.
- Nutzen Sie sowohl Offline- als auch kontinuierliche Bewertung — Tests vor der Veröffentlichung decken offensichtliche Probleme auf, aber der Wert der Plattform ist am größten, wenn Teams auch Änderungen nach der Bereitstellung überwachen.
- Passen Sie Metriken an den geschäftlichen Kontext an — Integrierte Metriken sind nützliche Ausgangspunkte, aber domänenspezifische Regeln und promptbasierte Prüfungen sind oft notwendig für aussagekräftige Akzeptanzkriterien.
- Priorisieren Sie risikoreiche Workflows für Agententests — Mehrstufige Systeme können durch kaskadierende Fehler scheitern, daher sollten Sie mit Aufgaben beginnen, die Tool-Aufrufe, sensible Daten oder kundenseitige Automatisierung beinhalten.
- Validieren Sie Retrieval getrennt von der Generierung — In RAG-Systemen ist es hilfreich, Kontextrelevanz und Retrieval-Qualität getrennt zu betrachten, bevor schlechte Ergebnisse ausschließlich dem LLM zugeschrieben werden.
OpenClaw-Fähigkeiten
Evidently AI könnte OpenClaw wahrscheinlich ergänzen, indem es Bewertungs-, Monitoring- und Regressionstest-Ebenen für KI-Workflows bereitstellt, die innerhalb eines breiteren Agenten-Ökosystems aufgebaut sind. Ein wahrscheinlicher Anwendungsfall wären OpenClaw-Agenten, die nach jeder Aktualisierung von Modell, Richtlinie oder Workflow automatisch Benchmark-Suiten für Prompts, RAG-Ketten oder Agentenaufgaben ausführen und anschließend Fehler nach Kategorien wie Halluzination, unsichere Ausgabe oder Retrieval-Abweichung zusammenfassen.
Ein weiterer wahrscheinlicher Einsatzbereich sind OpenClaw-Fähigkeiten mit Fokus auf KI-Governance-Prozesse: das Generieren adversarialer Testsets, das Überprüfen von Drift-Dashboards, das Weiterleiten von Vorfällen und das Empfehlen von Abhilfemaßnahmen für Prompt Engineers, ML-Ingenieure oder Product Owner. Bei guter Kombination könnte diese Paarung KI-Teams dabei helfen, von ad hoc durchgeführten Tests zu wiederholbaren Bewertungsprozessen überzugehen, insbesondere in Umgebungen, in denen LLM-Apps und ML-Systeme häufig aktualisiert werden.
Einbettungscode
Teile dieses KI-Tool auf deiner Website oder in deinem Blog, indem du den folgenden Code kopierst und einfügst. Das eingebettete Widget aktualisiert sich automatisch.
<iframe src="https://www.aimyflow.com/ai/evidentlyai-com/embed" width="100%" height="400" frameborder="0"></iframe>
Ähnliche Tools entdecken
Kostenloser KI-Fotoeditor: Bilder online bearbeiten und generieren | Pokecut
Pokecut ist ein KI-Fotoeditor, mit dem Nutzer Hintergründe entfernen, Bilder verbessern und Visuals online erstellen können – ideal für E-Commerce-Händler, Marketer und Creator mit Bedarf an schnell einsatzbereiten Assets. Es beschleunigt die Bildproduktion und reduziert manuellen Bearbeitungsaufwand.
Qoder - Die agentische Coding-Plattform
Qoder ist eine agentische Coding-Plattform, mit der Entwickler Codebasen verstehen und Softwareaufgaben mit KI-Agenten ausführen können – ideal für professionelle Softwareentwickler und Entwicklungsteams. Sie steigert den Engineering-Durchsatz durch starken Code-Kontext und zuverlässigere Aufgabenerledigung.
Seedance 2.0
Seedance 2.0 ist ByteDances KI-Videomodell zur Erstellung hochwertiger Videos aus Prompts und multimodalen Eingaben, entwickelt für Creator, Entwickler und Medienteams.
Struct | Automatisiere dein On-Call-Runbook
Struct ist ein KI-On-Call-Agent, der Engineering-Alerts und Bugs durch Analyse von Logs, Metriken, Traces und Codebasen untersucht – für Softwareentwickler und SRE-Teams.
Handit.ai — Die Open-Source-Engine, die Ihre KI-Agenten automatisch verbessert
Handit.ai ist eine Open-Source-Optimierungsengine für KI-Agenten, die Entscheidungen auswertet, bessere Prompts und Datensätze erstellt und Änderungen per A/B-Tests prüft. So verbessern KI- und Produktteams die Agentenqualität schneller und behalten mehr Kontrolle im Produktivbetrieb.
Kostenloser KI-Grammatikprüfer - LanguageTool
LanguageTool ist ein KI-gestützter Grammatik- und Schreibassistent, der Grammatik, Rechtschreibung, Zeichensetzung und Stil in mehr als 30 Sprachen prüft. Das hilft Studierenden, Berufstätigen und mehrsprachigen Teams, klarer zu schreiben und schneller zu lektorieren.
Trace
Trace ist ein Software-Tool für digitale Workflows, das Teams dabei unterstützt, Arbeit besser zu organisieren, zu überwachen oder zu analysieren.
Die KI für Problemlöser | Claude von Anthropic
Claude von Anthropic ist ein KI-Assistent für Problemlöser, der Nutzern dabei hilft, komplexe Aufgaben wie Schreiben, Programmieren, Datenanalyse, Recherche und die Organisation von Aufgaben zu bewältigen, vor allem für Fachkräfte, Entwickler und Teams, die anspruchsvolle Projekte bearbeiten. In KI-gestützten Arbeitsabläufen kann er Wissensarbeiter und Softwareteams dabei unterstützen, schneller von der Analyse zur Umsetzung zu gelangen, während die Kontrolle über Freigaben und den Dateizugriff bei den Menschen bleibt.