
Überarbeitet
Dieses Tool bewerten
Durchschnittsbewertung
Gesamtstimmen
Wähle deine Bewertung (1-10):
Detailinformationen
Was
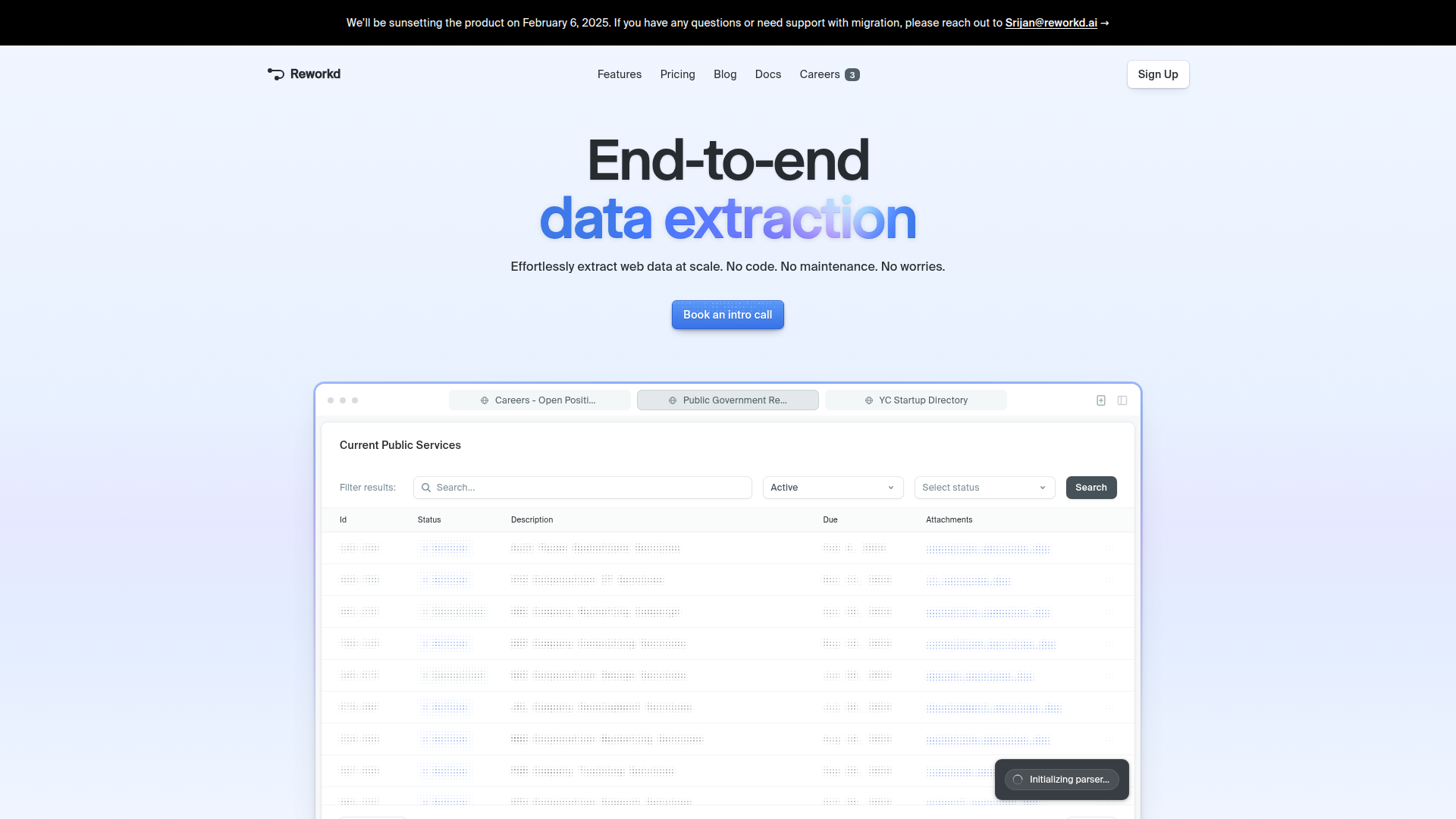
Reworkd ist ein End-to-End-Produkt zur Extraktion von Webdaten, das entwickelt wurde, um die Erfassung, das Parsing, die Validierung und die Bereitstellung von Daten aus Websites zu automatisieren. Die Seite positioniert es als No-Code-System, das zentrale Schritte des Scraping-Workflows übernimmt, etwa das Scannen von Websites, das Generieren von Extraktionscode, das Ausführen von Extraktoren und die Ausgabe strukturierter Ergebnisse.
Es scheint für Teams gedacht zu sein, die Webdaten in großem Maßstab benötigen, ohne intern eine Scraping-Infrastruktur aufzubauen und zu warten. Basierend auf den gezeigten Beispielen gehören wahrscheinlich Betriebs-, Forschungs-, Daten- und Vertriebsteams zu den Nutzern, die öffentliche Websites, Verzeichnisse, Listen, regulatorische Inhalte oder Dokumente überwachen; die Seite definiert die Zielkundensegmente jedoch nicht im Detail. Das Produkt wird zudem ausdrücklich am 6. Februar 2025 eingestellt.
Funktionen
- Automatisierte Generierung von Extraktionscode — Das Produkt gibt an, dass KI-Agenten Webseiten verstehen und Code zur Extraktion der angeforderten Daten erzeugen, wodurch die manuelle Entwicklung von Scrapern reduziert wird.
- Automatisierung der End-to-End-Datenpipeline — Reworkd gibt an, Websites zu scannen, Extraktoren auszuführen, Ergebnisse zu validieren und Daten in einem einzigen System auszugeben, was mehrstufige Scraping-Prozesse vereinfachen kann.
- Selbstheilende Scraper — Die Plattform behauptet, Änderungen an Websites zu erkennen und Datenausfälle automatisch zu beheben, was den Wartungsaufwand reduziert, wenn sich Quellseiten ändern.
- Unterstützung mehrerer Datentypen — Laut der Seite kann das Produkt Text, Bilder und Dokumente abrufen, was für Workflows zur Extraktion gemischter Inhalte nützlich ist.
- Analyse-Dashboard — Reworkd bietet interaktive Analysen, um nachzuverfolgen, was extrahiert wird, was funktioniert und was sich zwischen Jobs verändert.
- No-Code-Workflow — Das Produkt wird als vollständig ohne Programmieraufwand für den Nutzer beschrieben, was die Einstiegshürden für nicht-technische Teams wahrscheinlich senkt.
Hilfreiche Tipps
- Produktabkündigung und Migration einplanen — Da das Produkt am 6. Februar 2025 eingestellt werden soll, sollte sich jede Bewertung auf Migrationsunterstützung, Exportkontinuität und eine Ersatzarchitektur konzentrieren.
- Extraktionsqualität auf repräsentativen Websites prüfen — Bei Tools dieser Kategorie sollte die Leistung über Paginierung, dynamische Inhalte, Anhänge und Website-Änderungen hinweg validiert werden, anstatt sich nur auf Aussagen auf der Startseite zu verlassen.
- Ausgabeformate und operative Zuständigkeit klären — Die Seite zeigt strukturierte Ausgaben, spezifiziert jedoch Liefermethoden, Orchestrierungssteuerungen oder Optionen für nachgelagerte Integrationen nicht vollständig; diese Bereiche müssten daher bestätigt werden.
- Wartungsverhalten bei realen Änderungen testen — Aussagen zur Selbstheilung sind wertvoll, aber Käufer sollten prüfen, wie Ausfälle in produktiven Workflows sichtbar gemacht, überprüft und korrigiert werden.
- Dokumentenlastige Anwendungsfälle separat bewerten — Die Website hebt die Extraktion von Dokumenten und öffentlichen Registern hervor, daher sollten Teams, die mit PDFs oder Anhängen arbeiten, die Tiefe der Dokumentenanalyse und die Verarbeitung von Metadaten bestätigen.
OpenClaw-Fähigkeiten
Innerhalb des OpenClaw-Ökosystems würde ein solches Produkt wahrscheinlich als Ebene zur Aufnahme von Webdaten für nachgelagerte Agenten und Entscheidungs-Workflows dienen. Wahrscheinliche Anwendungsfälle umfassen Agenten, die öffentliche Ausschreibungsseiten überwachen, regulatorische Einreichungen sammeln, strukturierte Datensätze aus Verzeichnissen extrahieren oder Änderungen in Listen und Anhängen verfolgen und die bereinigten Daten anschließend an Fähigkeiten zur Anreicherung, Klassifizierung oder Benachrichtigung weitergeben.
Da die Seite keine native OpenClaw-Integration nennt, ist jede Verbindung hier ein abgeleiteter Workflow und keine bestätigte Funktion. Dennoch könnte eine praktische Kombination OpenClaw-Agenten umfassen, die Extraktionsjobs planen, Anomalien prüfen, Website-Änderungen zusammenfassen, Dokumente zur Analyse weiterleiten und branchenspezifische Aktionen für Analysten, Compliance-Teams, Marktforscher oder Workflows im Bereich Public-Sector-Intelligence auslösen. Dadurch würde Arbeit von manueller Seitenprüfung und fragilen Skripten hin zu verwalteten, agentengestützten Datenoperationen verlagert.
Einbettungscode
Teile dieses KI-Tool auf deiner Website oder in deinem Blog, indem du den folgenden Code kopierst und einfügst. Das eingebettete Widget aktualisiert sich automatisch.
<iframe src="https://www.aimyflow.com/ai/reworkd-ai/embed" width="100%" height="400" frameborder="0"></iframe>
Ähnliche Tools entdecken
Bright Data für KI – Verbinden Sie Ihre KI mit dem Web
Bright Data für KI ist eine Webdatenplattform, die KI-Teams dabei unterstützt, strukturierte Echtzeit- und Trainingsdaten aus dem Web über APIs, Remote-Browser, Datensätze und Automatisierungstools zu durchsuchen, zu crawlen, zu extrahieren und zu erfassen. Für KI-Ingenieure, Data Scientists und Entwickler von Agenten kann sie den Aufwand für den Aufbau von Webzugriffs- und Datenerfassungspipelines reduzieren, sodass sie sich stärker auf das Modellverhalten und die Anwendungslogik konzentrieren können.
Autonome KI für Datenteams | Databricks
Databricks Genie Code ist ein autonomes KI-Tool im Databricks-Arbeitsbereich, das Datenteams dabei unterstützt, Workflows für Data Science, maschinelles Lernen, Data Engineering, Analytik und Dashboards mithilfe natürlicher Sprache und des Datenkontexts des Unternehmens zu planen, auszuführen und zu warten. Für Data Engineers, Data Scientists und Analysten kann es den manuellen Orchestrierungsaufwand reduzieren, indem es die Arbeit auf der Grundlage verwalteter Metadaten verankert und Produktionspipelines, Modelle und BI-Assets proaktiv unterstützt.
BlazorData – Startseite
BlazorData ist eine auf Blazor basierende Datenorchestrierungsplattform für Datenmanagement, Transformation und Workflow-Automatisierung auf Unternehmensebene, die sich hauptsächlich an Teams richtet, die strukturierte Datenprozesse in geschäftlichen oder technischen Umgebungen verwalten. In Workflows des KI-Zeitalters kann sie Daten- und Operations-Fachleuten dabei helfen, sauberere und zuverlässigere Pipelines zu organisieren, die Automatisierung und nachgelagerte Analysen unterstützen.
Blackshark.ai – KI-Infrastruktur für die physische Welt
Blackshark.ai ist eine KI-gestützte Geodaten-Infrastrukturplattform, die Satelliten-, Luft-, Drohnen- und Sensordatenbilder in strukturierte Weltmodelle und simulationsbereite 3D-Umgebungen für Regierungs- und Unternehmensteams umwandelt, die mit großskaligen Daten der physischen Welt arbeiten. Für Geodatenanalysten, Einsatzplaner im Katastrophenschutz und Simulationsteams kann sie die Erkennung von Veränderungen, das Lagebewusstsein und das KI-Training beschleunigen, indem sie massive Bilddatenströme in operative Erkenntnisse umwandelt.
Startseite | Kubit
Lager-native Analytics, die Snowflake, Databricks, BigQuery und ClickHouse direkt abfragen. Echtzeit-Einblicke mit regulierten, erklärbarer KI.
Erstellen Sie in Sekundenschnelle kostenlos SQL-Abfragen – SQLAI.ai
SQLAI.ai ist ein KI-SQL-Assistent, der Analysten, Dateningenieuren, Entwicklern und Datenteams dabei hilft, SQL- oder NoSQL-Abfragen aus natürlicher Sprache über viele Datenbank-Engines hinweg zu generieren, zu optimieren, zu validieren, zu formatieren, zu erklären und auszuführen. Für Analyse- und Engineering-Arbeiten kann es die Zeit für das Erstellen und Überprüfen von Abfragen verkürzen, indem es schemabewusste Generierung mit Validierung und gut verständlichen Erklärungen kombiniert.
Sentimentanalyse mit MindsDB und OpenAI unter Verwendung von SQL – MindsDB
Dieses MindsDB-Tutorial zeigt Entwicklern, wie sie mit SQL ein von OpenAI unterstütztes Sentiment-Analysemodell innerhalb einer Datenbank erstellen und Textbewertungen als positiv, neutral oder negativ klassifizieren können. Für Data Engineers und Anwendungsentwickler kann dieser Ansatz die Integration von KI-gestützter Textanalyse in Datenbank-Workflows beschleunigen, ohne eine separate Machine-Learning-Pipeline aufbauen zu müssen.

OSSUS
OSSUS ist eine selbstheilende Dateninfrastrukturplattform, die Unternehmen dabei unterstützt, fragmentierte Datensätze in vertrauenswürdige, agentenfähige Systeme der Wahrheit umzuwandeln, vor allem für Teams, die für Daten- und KI-Grundlagen verantwortlich sind. Mit zunehmender Verbreitung von KI kann sie Fachkräften aus den Bereichen Daten, Analytik und Engineering helfen, die Zuverlässigkeit zu verbessern, indem sie KI-Systemen sauberere, verlässlichere Informationen als Grundlage zur Verfügung stellt.