
Vanna 2.0 – Erstellen Sie Agenten, die Ihre Nutzer tatsächlich verwenden können
Dieses Tool bewerten
Durchschnittsbewertung
Gesamtstimmen
Wähle deine Bewertung (1-10):
Detailinformationen
Was
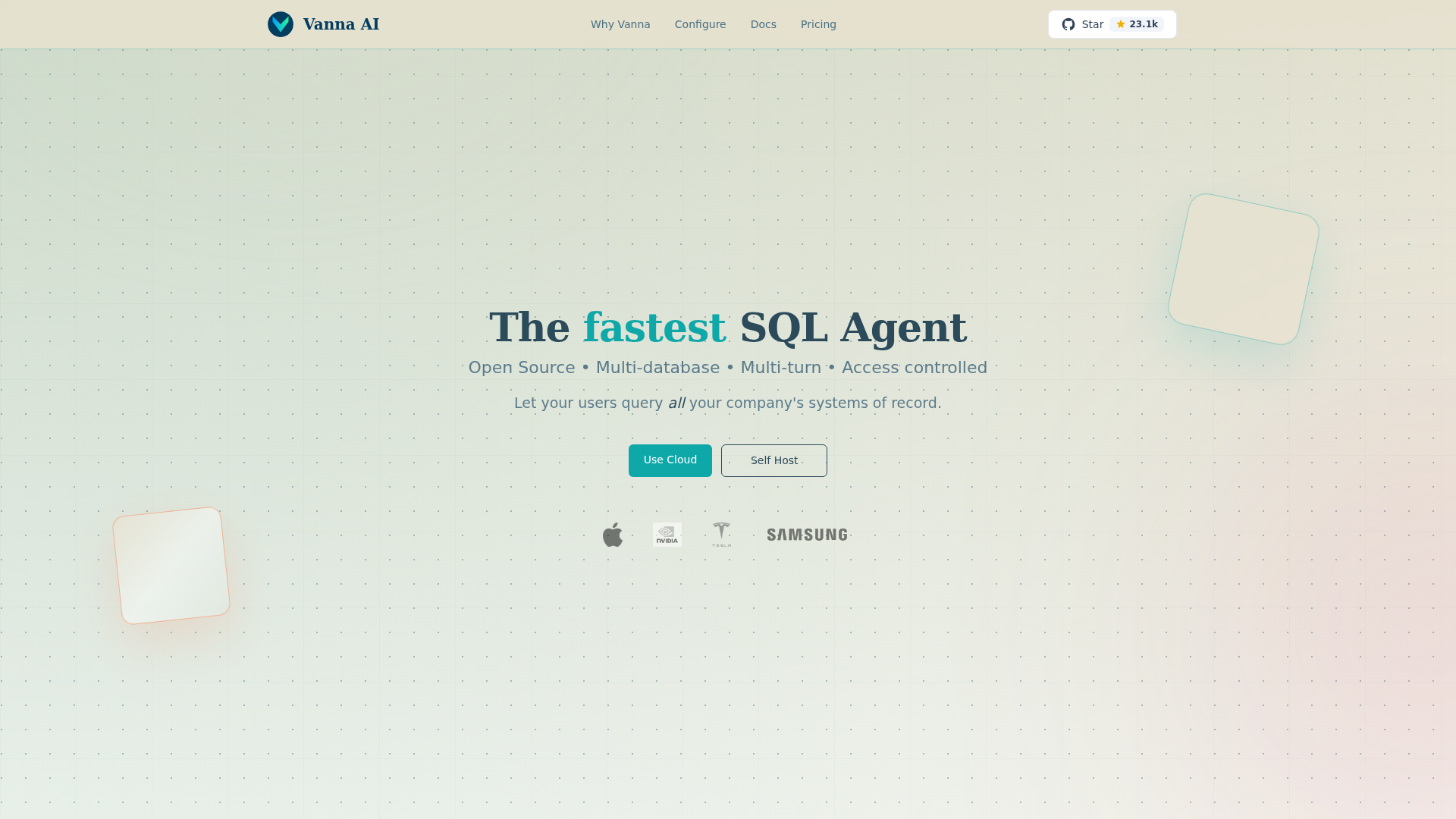
Vanna 2.0 ist ein Open-Source-SQL-Agenten-Framework, mit dem Nutzer Unternehmensdatensysteme in natürlicher Sprache abfragen und Antworten durch KI-gestützte SQL-Generierung erhalten können. Es wird als schneller Weg positioniert, datenbankorientierte Agenten zu entwickeln, die sowohl von technischen als auch von nichttechnischen Nutzern verwendet werden können, mit Unterstützung für Multi-Datenbank-, Multi-Turn- und zugriffskontrollierte Bereitstellungen.
Das Produkt scheint sich an Teams zu richten, die strukturierte Daten innerhalb einer Organisation leichter zugänglich machen möchten, ohne dass jeder Nutzer SQL manuell schreiben muss. Der zentrale Ablauf besteht darin, einen LLM-Anbieter und eine Datenbank zu verbinden, den Stack zu konfigurieren und Vanna zu verwenden, um Nutzerfragen systemübergreifend in SQL für führende Datensysteme zu übersetzen, wobei optionale gehostete Admin-Funktionen über Vanna Cloud verfügbar sind.
Funktionen
- Generierung von SQL aus natürlicher Sprache — Wandelt Nutzerfragen in SQL um, damit Teams weniger Zeit mit dem Schreiben von Abfragen und mehr Zeit mit der Interpretation der Ergebnisse verbringen.
- Unterstützung mehrerer Datenbanken — Funktioniert mit Datenbanken wie SQLite, PostgreSQL, MySQL, Snowflake und BigQuery, was Organisationen dabei hilft, ein Framework über verschiedene Datenumgebungen hinweg zu nutzen.
- Flexibilität bei LLM-Anbietern — Unterstützt mehrere Modellanbieter wie Anthropic, OpenAI, Gemini und Ollama und verringert damit die Abhängigkeit von einem einzelnen Modell-Stack.
- Multi-Turn-Interaktion — Unterstützt konversationelle Workflows, was nützlich ist, wenn Nutzer Fragen über mehrere Schritte hinweg verfeinern müssen, statt einmalig eine perfekte Abfrage zu schreiben.
- Zugriffskontrolle und Admin-Tools — Optionale gehostete Funktionen umfassen Zugriffskontrolle, Observability, Audit-Logs, Agentenspeicher, Dateispeicherung und Datenaufbewahrung für einen kontrollierteren Produktionseinsatz.
- Open Source und Self-Hosting-Option — Bietet einen OSS-Weg neben Cloud- und Self-Hosted-Nutzung, was Teams helfen kann, die mehr Kontrolle über die Bereitstellung und weniger Vendor Lock-in wünschen.
Hilfreiche Tipps
- Semantische Genauigkeit früh validieren — Bei jedem NL-to-SQL-Produkt ist das wichtigste Bewertungskriterium nicht nur, ob SQL ausgeführt werden kann, sondern ob damit die Geschäftsfrage korrekt beantwortet wird.
- Mit einem eng begrenzten Schemascope starten — Die anfängliche Einführung ist in der Regel einfacher, wenn der Agent zunächst auf einige wenige gut dokumentierte Tabellen oder Systeme beschränkt wird, bevor er auf breitere Unternehmensdaten ausgeweitet wird.
- Zugriffsgrenzen sorgfältig definieren — Da das Produkt dafür ausgelegt ist, führende Datensysteme über natürliche Sprache zugänglich zu machen, sollten rollenbasierte Sichtbarkeit und Auditierbarkeit vor einem breiten Rollout überprüft werden.
- Modellauswahl an Bereitstellungsanforderungen ausrichten — Vanna unterstützt mehrere LLM-Anbieter, daher sollten Teams Leistung, Datenschutzprofil, Latenz und Hosting-Präferenzen mit ihren eigenen Anforderungen vergleichen.
- Gehostete Admin-Funktionen als Governance-Ebene betrachten — Funktionen wie Observability, Logs, Speicher und Aufbewahrung sind am wertvollsten, wenn das Produkt über Prototypen hinaus in Produktions-Workflows eingesetzt wird.
OpenClaw-Fähigkeiten
Vanna könnte gut in das OpenClaw-Ökosystem als Ebene für strukturiertes Daten-Reasoning für Agenten passen, die operative, finanzielle, produktbezogene oder Support-Fragen aus Unternehmensdatenbanken beantworten müssen. Ein wahrscheinlicher Anwendungsfall wäre eine OpenClaw-Fähigkeit, die eine Nutzeranfrage in einen gesteuerten SQL-Workflow übersetzt, Ergebnisse aus freigegebenen Systemen abruft und die Ausgabe anschließend in Zusammenfassungen, Dashboards oder Folgeaktionen formatiert. Auf der Seite wird keine native OpenClaw-Integration beschrieben, daher sollte dies eher als wahrscheinliches Workflow-Muster denn als bestätigte Fähigkeit betrachtet werden.
Auf Vanna basierende OpenClaw-Agenten könnten Copiloten für Datenanalysten, interne Business-Intelligence-Assistenten, Revenue-Operations-Agenten oder Support-Reporting-Workflows unterstützen. In der Praxis könnte diese Kombination Organisationen dabei helfen, sich von statischen Dashboards hin zu konversationellem Datenzugriff zu bewegen, bei dem Geschäftsnutzer direkt Fragen stellen und OpenClaw die begleitenden Schritte wie Berechtigungsprüfungen, Prompt-Routing, Erklärungsgenerierung und Eskalation an menschliche Analysten bei geringer Sicherheit orchestriert.
Einbettungscode
Teile dieses KI-Tool auf deiner Website oder in deinem Blog, indem du den folgenden Code kopierst und einfügst. Das eingebettete Widget aktualisiert sich automatisch.
<iframe src="https://www.aimyflow.com/ai/vanna-ai/embed" width="100%" height="400" frameborder="0"></iframe>
Ähnliche Tools entdecken
Bright Data für KI – Verbinden Sie Ihre KI mit dem Web
Bright Data für KI ist eine Webdatenplattform, die KI-Teams dabei unterstützt, strukturierte Echtzeit- und Trainingsdaten aus dem Web über APIs, Remote-Browser, Datensätze und Automatisierungstools zu durchsuchen, zu crawlen, zu extrahieren und zu erfassen. Für KI-Ingenieure, Data Scientists und Entwickler von Agenten kann sie den Aufwand für den Aufbau von Webzugriffs- und Datenerfassungspipelines reduzieren, sodass sie sich stärker auf das Modellverhalten und die Anwendungslogik konzentrieren können.
Autonome KI für Datenteams | Databricks
Databricks Genie Code ist ein autonomes KI-Tool im Databricks-Arbeitsbereich, das Datenteams dabei unterstützt, Workflows für Data Science, maschinelles Lernen, Data Engineering, Analytik und Dashboards mithilfe natürlicher Sprache und des Datenkontexts des Unternehmens zu planen, auszuführen und zu warten. Für Data Engineers, Data Scientists und Analysten kann es den manuellen Orchestrierungsaufwand reduzieren, indem es die Arbeit auf der Grundlage verwalteter Metadaten verankert und Produktionspipelines, Modelle und BI-Assets proaktiv unterstützt.
BlazorData – Startseite
BlazorData ist eine auf Blazor basierende Datenorchestrierungsplattform für Datenmanagement, Transformation und Workflow-Automatisierung auf Unternehmensebene, die sich hauptsächlich an Teams richtet, die strukturierte Datenprozesse in geschäftlichen oder technischen Umgebungen verwalten. In Workflows des KI-Zeitalters kann sie Daten- und Operations-Fachleuten dabei helfen, sauberere und zuverlässigere Pipelines zu organisieren, die Automatisierung und nachgelagerte Analysen unterstützen.
Blackshark.ai – KI-Infrastruktur für die physische Welt
Blackshark.ai ist eine KI-gestützte Geodaten-Infrastrukturplattform, die Satelliten-, Luft-, Drohnen- und Sensordatenbilder in strukturierte Weltmodelle und simulationsbereite 3D-Umgebungen für Regierungs- und Unternehmensteams umwandelt, die mit großskaligen Daten der physischen Welt arbeiten. Für Geodatenanalysten, Einsatzplaner im Katastrophenschutz und Simulationsteams kann sie die Erkennung von Veränderungen, das Lagebewusstsein und das KI-Training beschleunigen, indem sie massive Bilddatenströme in operative Erkenntnisse umwandelt.
Erstellen Sie in Sekundenschnelle kostenlos SQL-Abfragen – SQLAI.ai
SQLAI.ai ist ein KI-SQL-Assistent, der Analysten, Dateningenieuren, Entwicklern und Datenteams dabei hilft, SQL- oder NoSQL-Abfragen aus natürlicher Sprache über viele Datenbank-Engines hinweg zu generieren, zu optimieren, zu validieren, zu formatieren, zu erklären und auszuführen. Für Analyse- und Engineering-Arbeiten kann es die Zeit für das Erstellen und Überprüfen von Abfragen verkürzen, indem es schemabewusste Generierung mit Validierung und gut verständlichen Erklärungen kombiniert.
Sentimentanalyse mit MindsDB und OpenAI unter Verwendung von SQL – MindsDB
Dieses MindsDB-Tutorial zeigt Entwicklern, wie sie mit SQL ein von OpenAI unterstütztes Sentiment-Analysemodell innerhalb einer Datenbank erstellen und Textbewertungen als positiv, neutral oder negativ klassifizieren können. Für Data Engineers und Anwendungsentwickler kann dieser Ansatz die Integration von KI-gestützter Textanalyse in Datenbank-Workflows beschleunigen, ohne eine separate Machine-Learning-Pipeline aufbauen zu müssen.

OSSUS
OSSUS ist eine selbstheilende Dateninfrastrukturplattform, die Unternehmen dabei unterstützt, fragmentierte Datensätze in vertrauenswürdige, agentenfähige Systeme der Wahrheit umzuwandeln, vor allem für Teams, die für Daten- und KI-Grundlagen verantwortlich sind. Mit zunehmender Verbreitung von KI kann sie Fachkräften aus den Bereichen Daten, Analytik und Engineering helfen, die Zuverlässigkeit zu verbessern, indem sie KI-Systemen sauberere, verlässlichere Informationen als Grundlage zur Verfügung stellt.
Unsiloed AI
Unsiloed AI ist eine Dokumentenverarbeitungsplattform, die multimodale unstrukturierte Daten wie PDFs, Tabellen, Präsentationsfolien und Bilder in strukturiertes JSON oder Markdown für LLMs, KI-Agenten und Automatisierung umwandelt, hauptsächlich für Entwickler, KI-Ingenieure und Datenteams in Unternehmen, in denen Genauigkeit entscheidend ist. In KI-Workflows kann sie Datenengineering-, ML- und Operations-Teams dabei helfen, den manuellen Parsing-Aufwand zu reduzieren und die Retrieval-Qualität zu verbessern, indem sie Dokumentstruktur, Hierarchie und Domänenkontext bewahrt.