标贝悦读-语音合成-在线文字转语音软件-专业的配音网站
Rate this Tool
Average Score
Total Votes
Select your score (1-10):
Detail Information
What
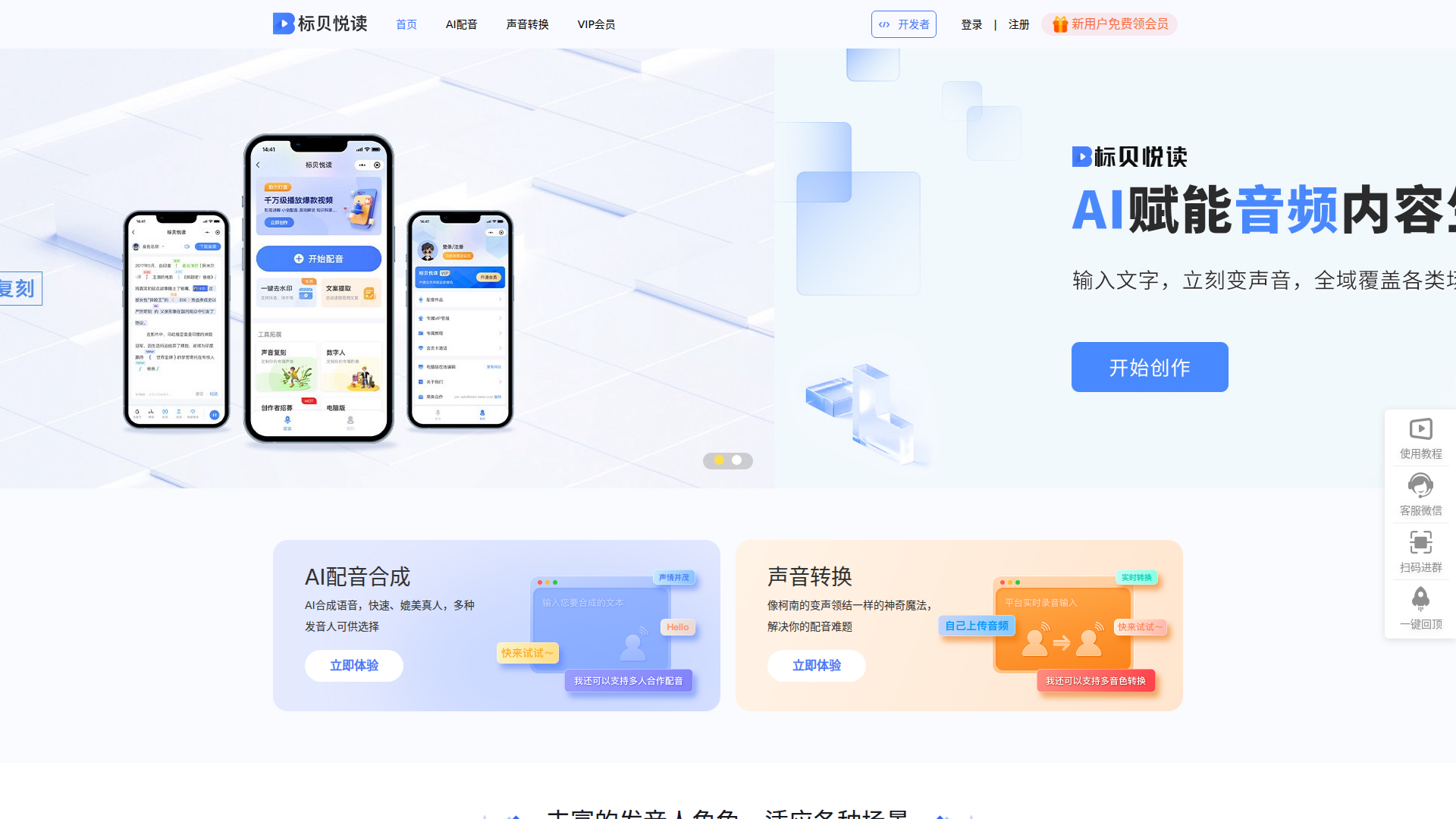
标贝悦读 is an online text-to-speech and voice dubbing product focused on AI配音合成 and 声音转换. Based on the page content, it serves content creators, businesses, and media production teams that need fast voiceover creation for videos, explainers, tutorials, and other spoken-content scenarios.
Its core workflow appears to center on entering text, selecting a voice, refining pronunciation and pacing, and generating spoken audio. The product is likely positioned as a professional Chinese-language dubbing website with both browser-based usage and developer-oriented access, although the page only briefly mentions API/SDK support and does not describe that capability in detail.
Features
- AI text-to-speech synthesis — Converts written text into speech with a range of selectable speakers, helping users create voiceovers without recording talent manually.
- Voice conversion — Supports converting one voice into a target voice, which is presented as a way to solve dubbing challenges beyond standard TTS.
- Multiple speaker personas — Offers male, female, and child-style voices with different tonal characteristics, making it easier to match narration style to content type.
- Polyphone correction — Helps adjust pronunciation for Chinese characters with multiple readings, improving accuracy in generated speech.
- Pause insertion and local speed control — Lets users shape rhythm and emphasis, which is useful for making synthetic narration sound more natural and easier to follow.
- Number reading, pinyin viewing, and multi-speaker dubbing — Adds control for numeric pronunciation, pronunciation review, and dialogue-style production in a single workflow.
Helpful Tips
- For Chinese-language dubbing tools, test polyphones, numbers, and sentence breaks early, because intelligibility often depends more on pronunciation control than on voice selection alone.
- If the project involves conversations, training content, or role-based scripts, prioritize products that support multi-speaker workflows rather than stitching separate clips manually.
- Voice conversion and TTS solve different problems; evaluate whether your team needs script-based narration, identity/style transfer, or both before standardizing on a workflow.
- The site mentions developer access, but implementation details are limited on this page, so technical buyers should verify API scope, file formats, and production constraints separately.
- Match voice persona to scenario carefully: instructional, commercial, and narrative content usually benefit from different pacing, tone, and age/gender presentation.
OpenClaw Skills
Within the OpenClaw ecosystem, this product could likely support skills for automated script-to-audio generation, multilingual content operations centered on Chinese narration, and batch production of voice assets for media teams. A likely use case would be an OpenClaw agent that takes a knowledge article, marketing script, or training lesson, selects an appropriate narrator profile, applies pronunciation and pacing rules, and returns a ready-to-edit voiceover draft.
A broader OpenClaw workflow could combine this kind of speech generation with script writing, content localization, video assembly, and QA review. If developer access is sufficiently exposed, teams in education, short-video publishing, e-commerce, or corporate training could build agents that turn structured text into branded audio libraries at scale; this is a likely workflow inference rather than a confirmed native integration from the page itself.
Embed Code
Share this AI tool on your website or blog by copying and pasting the code below. The embedded widget will automatically update with the latest information.
<iframe src="https://www.aimyflow.com/ai/yuedu-data-baker-com/embed" width="100%" height="400" frameborder="0"></iframe>