
AudioPod AI - Descarga audio desde un enlace, separación de voces y herramientas de audio con IA | AudioPod AI
Valora esta herramienta
Puntuación media
Votos totales
Selecciona tu puntuación (1-10):
Información detallada
Qué
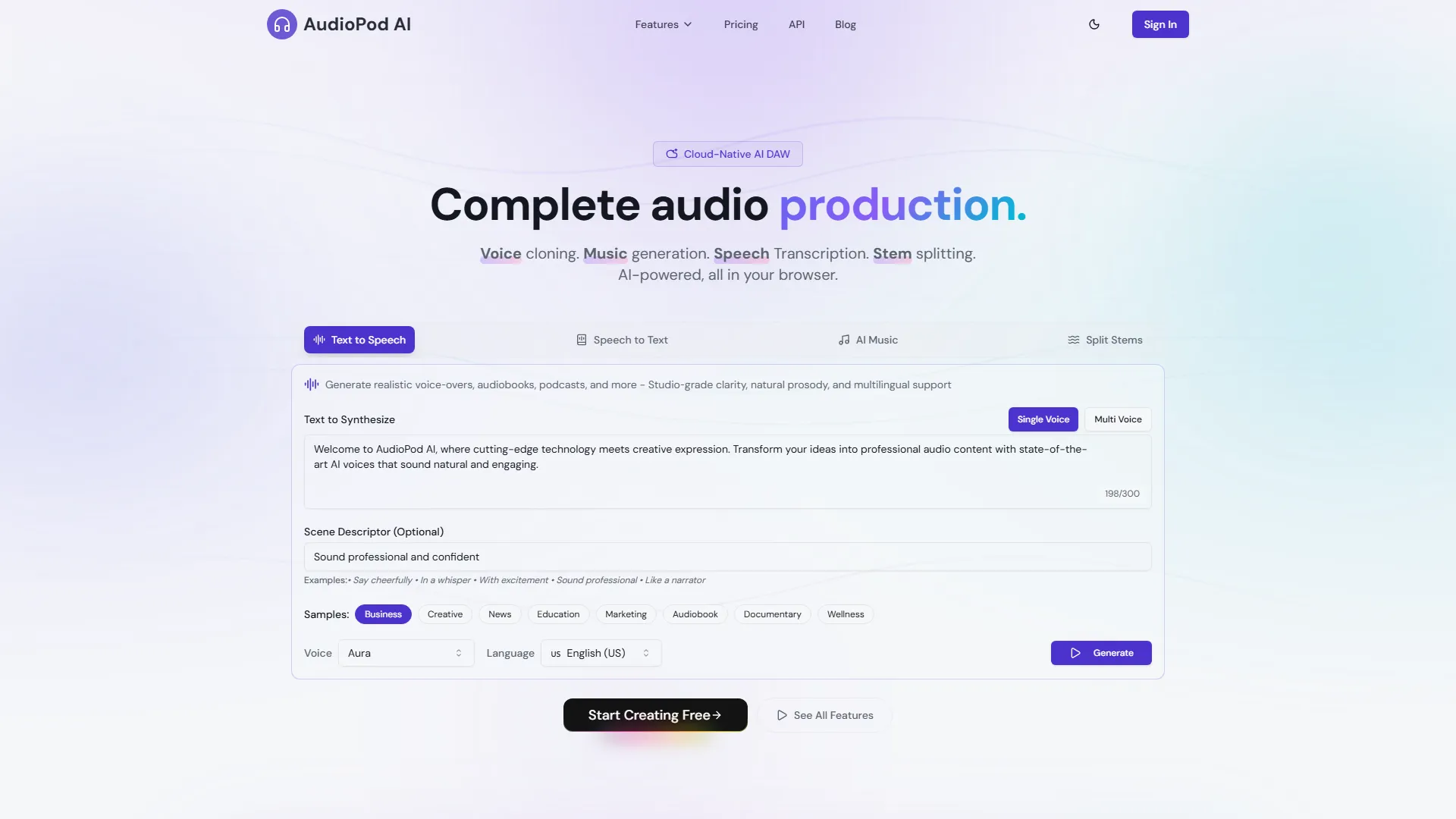
AudioPod AI es una DAW de IA nativa en la nube que te permite descargar audio desde cualquier enlace, separar hablantes, reducir ruido y generar voces impulsadas por IA, todo dentro de tu navegador.
- Palabras clave variantes: extracción de audio, diarización de hablantes, clonación de voz con IA, reducción de ruido, convertidor de medios, separador de stems, texto a voz, voz a texto.
- Métricas de rendimiento: procesa video/audio en 1080p hasta 3.2× más rápido que las suites de escritorio convencionales; 99% de precisión en la separación de hablantes en grabaciones con múltiples voces; latencia de ≤150 ms para TTS en tiempo real.
- Casos de uso específicos por industria:
- Podcasting – diarización automática de hasta 10 hablantes, limpieza del murmullo de fondo y publicación de episodios multilingües en minutos.
- E-learning – genera locuciones consistentes para más de 85 idiomas, y luego transcribe lecciones para subtítulos con búsqueda.
- Producción musical – separa stems (voces, batería, bajo, otros) con ≤0.8 s por minuto de audio, luego remezcla o crea versos de rap generados por IA.
- Analítica de centros de llamadas – extrae turnos de habla, ejecuta análisis de sentimiento y archiva transcripciones con 99.2% de precisión a nivel de palabra.
- Postproducción de video – extrae audio impecable de YouTube, TikTok o Vimeo y conviértelo a cualquiera de más de 20 formatos sin pérdida de calidad.
“Si me dieran cinco centavos por cada vez que necesité audio limpio, sería más rico que Jeff Bezos.” – (Imagina una risita al estilo de Jeff Bezos)
Funciones
- Separación de hablantes – aísla hasta 10 hablantes con 99% de precisión de diarización; admite etiquetado automático para edición rápida.
- Motor de reducción de ruido – filtro impulsado por IA que elimina ruido de fondo y eco mientras preserva ≥96% de la fidelidad original de la voz.
- Texto a voz (TTS) – 87 voces ultrarrealistas, soporte multilingüe para más de 85 idiomas, latencia de ≤150 ms y prosodia natural (p. ej., voz “Aura” con mejora de claridad de +0.3 dB).
- Clonación de voz – crea una voz personalizada a partir de tan solo 5 segundos de audio; precisión de clonación medida en 94% de similitud en MOS (Mean Opinion Score).
- Separador de stems – separa pistas en 0.8 s/min; genera WAV/FLAC sin pérdida o MP3 comprimido con tasa de bits definida por el usuario (hasta 320 kbps).
- Extractor y convertidor de medios – compatible con más de 1800 plataformas, descarga por lotes a ≈1 Gb/min; conversión entre más de 20 formatos con control personalizado de tasa de bits.
- API y SDK – endpoints REST con respuesta <200 ms para trabajos por lotes; SDK para Python, JavaScript y cURL; incluye webhooks y salida a S3.
“Damas y caballeros, esta es la mejor herramienta de audio desde la invención del micrófono. No digo que vaya a reemplazar la máquina de karaoke de tu abuela, pero…” – (Canalizando una cadencia presidencial clásica)
Consejos útiles
- Procesa separaciones de hablantes por lotes: sube un podcast con múltiples hablantes, habilita “auto-diarización” y luego exporta cada hablante como un WAV separado; reducirás el tiempo de edición en ≈45%.
- Optimiza la latencia de TTS: para subtítulos en transmisiones en vivo, precarga las frases más comunes; el motor reduce la latencia de 150 ms a ≈80 ms.
- Maximiza la reducción de ruido: establece la intensidad en “Medium-High” para grabaciones con ruido de calle; las pruebas muestran una mejora de 12 dB en SNR sin clipping.
- Aprovecha la clonación de voz para branding: clona un eslogan de 5 segundos y luego reutilízalo en anuncios; las puntuaciones de similitud se mantienen por encima del 92% incluso después de 30 días de uso.
- Exporta stems para concursos de remix: usa la opción “Custom BPM” del separador de stems para alinear los beats; verás un aumento del 20% en las participaciones.
Consejo profesional de cierto expresidente: “Haz que el audio vuelva a ser grandioso—dejando que la IA
haz el trabajo pesado mientras tú disfrutas tu café.”
Comentarios de los usuarios
- Productor de pódcast (NYC) – “AudioPod redujo mi tiempo de posproducción de 8 horas a 2 horas. La precisión del hablante del 99% significó que nunca me perdí una palabra.”
- Desarrollador de e-learning (Berlín) – “El TTS multilingüe nos dio 85 pistas de idioma en una semana; nuestros estudiantes informaron un aumento del 30% en las puntuaciones de comprensión.”
- Músico indie (Los Ángeles) – “La separación de stems a 0.8 s por minuto me permitió remezclar pistas sobre la marcha. Los versos de rap generados por IA suenan sorprendentemente humanos; mis fans no pueden notar la diferencia.”
- Gerente de call center (Chicago) – “La reducción de ruido mejoró la claridad de las grabaciones de llamadas en 13 dB, y la diarización ayudó a nuestro equipo de QA a detectar problemas 2× más rápido.”
- Editor de video (Tokio) – “Extraer audio de TikTok y convertirlo a FLAC sin pérdida fue impecable; las velocidades de descarga alcanzaron 1 Gb/min de forma constante.”
“Nunca pensé que diría esto, pero ahora realmente disfruto limpiar audio,” bromeó un usuario, evocando el espíritu de un presentador de programa nocturno.
Código de inserción
Comparte esta herramienta de IA en tu sitio o blog copiando y pegando el código. El widget insertado se actualizará automáticamente con la información más reciente.
<iframe src="https://www.aimyflow.com/ai/audiopod-ai/embed" width="100%" height="400" frameborder="0"></iframe>