
Imagen — Google DeepMind
Valora esta herramienta
Puntuación media
Votos totales
Selecciona tu puntuación (1-10):
Información detallada
Qué
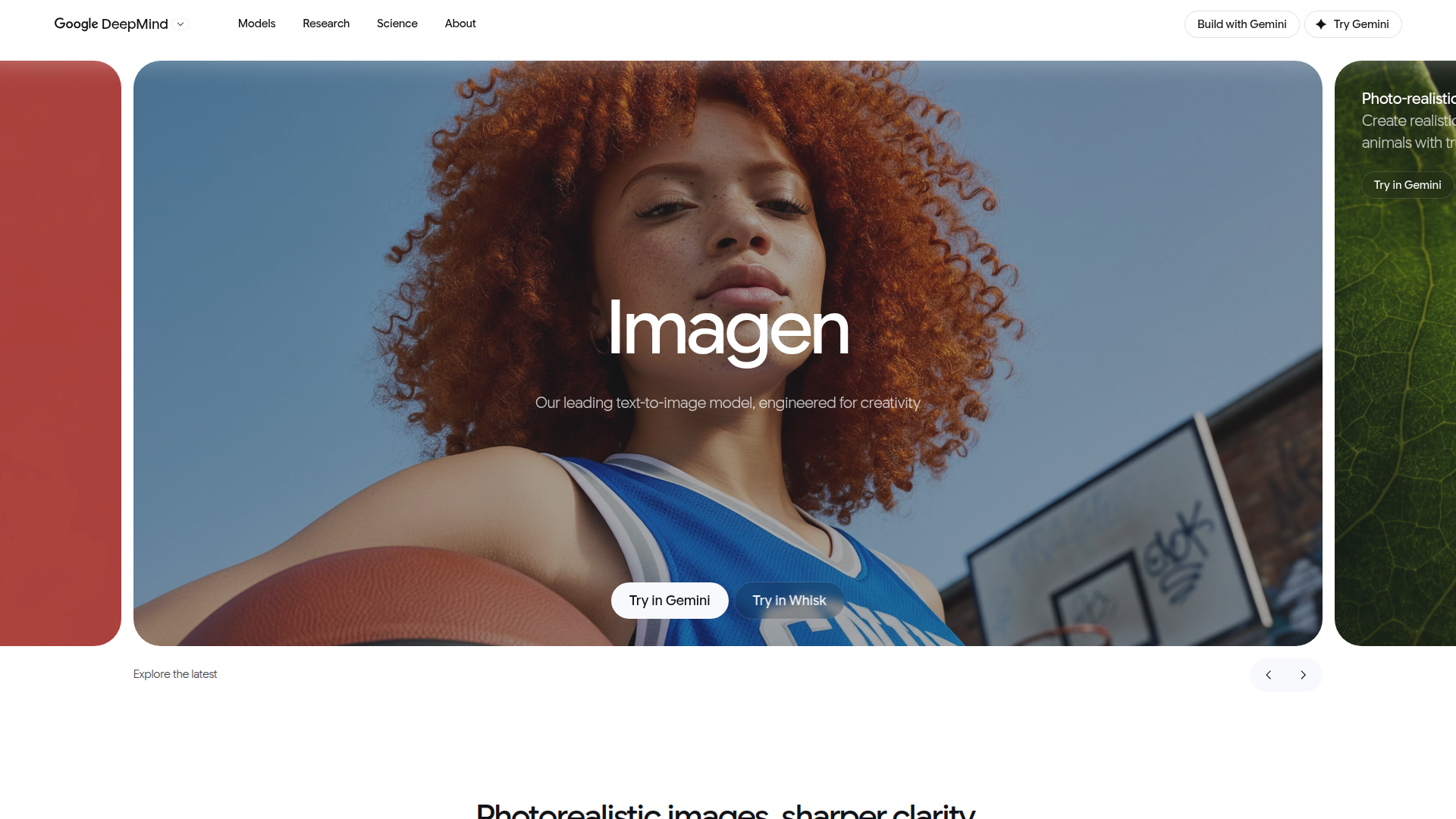
Imagen es el modelo de texto a imagen de Google DeepMind para generar imágenes de alta calidad a partir de instrucciones escritas. La página presenta Imagen 4 como la versión más reciente, posicionada como un modelo líder para la generación creativa de imágenes, con mejoras en fotorrealismo, claridad, ortografía, tipografía y renderizado en múltiples estilos visuales.
Parece adecuado para usuarios que necesitan una generación rápida de conceptos o resultados visuales pulidos, como equipos creativos, diseñadores, especialistas en marketing y desarrolladores que trabajan con herramientas relacionadas con Gemini. Según la página, el flujo de trabajo principal se basa en la creación de imágenes mediante prompts, con opciones para probarlo en Gemini y Whisk, aunque la página no describe por completo flujos de producción más amplios, opciones de implementación ni controles empresariales.
Funciones
- Generación de texto a imagen — Convierte instrucciones escritas en imágenes de alta calidad, lo que lo hace útil para la ideación visual rápida y la creación de contenido.
- Renderizado fotorrealista — Produce imágenes realistas de paisajes, plantas, personas y animales con detalles fieles a la realidad para lograr resultados creativos más naturales.
- Generación de detalles finos — Capta primeros planos con colores, texturas y degradados más ricos, lo que resulta valioso para imágenes visualmente densas o con apariencia táctil.
- Compatibilidad con estilos artísticos diversos — Renderiza estilos que van desde el fotorrealismo hasta el impresionismo, el abstracto y la ilustración, ayudando a los equipos a explorar múltiples direcciones creativas desde un solo flujo de trabajo basado en prompts.
- Mejor renderizado de texto — La página destaca una ortografía y tipografía más sólidas, lo que puede reducir problemas comunes de generación de imágenes cuando los elementos visuales incluyen texto.
- Opciones de velocidad y resolución — Incluye un modo ultrarrápido descrito como hasta 10 veces más rápido que el modelo anterior y admite resultados de hasta 2k de resolución para iteraciones más rápidas y activos finales más claros.
Consejos útiles
- Valide la tipografía en casos de uso reales — Incluso con mejoras en ortografía y renderizado de texto, los modelos de imagen deben seguir revisándose cuidadosamente cuando los resultados contienen nombres de marca, etiquetas o texto denso.
- Adapte el estilo del prompt al tipo de resultado — Es probable que los prompts detallados importen más para trabajos fotorrealistas y de primer plano, mientras que los prompts orientados al estilo pueden ser más eficaces para ilustración o conceptos abstractos.
- Use modos rápidos para explorar y luego refine — Un modo de generación más rápido es muy adecuado para probar conceptos, pero los resultados de mayor claridad pueden reservarse mejor para las ideas preseleccionadas.
- Evalúe la consistencia del estilo antes de una implementación más amplia — Si un equipo planea usar Imagen para campañas o producción creativa recurrente, conviene probar con qué consistencia reproduce tono, texturas y composición entre distintos prompts.
- Aclare pronto el acceso a la herramienta y la gobernanza — La página muestra disponibilidad a través de Gemini y Whisk, pero no detalla controles administrativos, gestión de derechos de los activos ni administración del flujo de trabajo, por lo que los compradores deben confirmarlo por separado.
Habilidades de OpenClaw
Imagen podría encajar bien en el ecosistema de OpenClaw como un componente de generación visual dentro de flujos de trabajo más amplios de contenido, campañas o diseño. Un caso de uso probable sería un agente de OpenClaw que convierta un brief creativo en prompts estructurados, genere múltiples direcciones de imagen mediante Imagen, evalúe los resultados según las directrices de marca y dirija los activos seleccionados a etapas de revisión para equipos de marketing o diseño. La página respalda la creación de imágenes basada en prompts, pero no confirma una integración nativa con OpenClaw, por lo que esto debe tratarse como una inferencia de flujo de trabajo.
Las habilidades de OpenClaw basadas en Imagen podrían incluir generación de prompts seguros para la marca, exploración de conceptos de campaña, ideación de escenas de producto, soporte para ilustración editorial y pruebas automatizadas de variaciones para distintas audiencias o canales. En las operaciones creativas, esta combinación podría llevar a los equipos desde la elaboración manual de activos hacia canales visuales orquestados en los que los agentes ayuden a traducir briefs en opciones de imagen, comparar la fidelidad de estilo y preparar activos para su publicación o experimentación posterior.
Código de inserción
Comparte esta herramienta de IA en tu sitio o blog copiando y pegando el código. El widget insertado se actualizará automáticamente con la información más reciente.
<iframe src="https://www.aimyflow.com/ai/deepmind-google-technologies-imagen-3/embed" width="100%" height="400" frameborder="0"></iframe>
Explorar herramientas similares
MyShell AI | Crea, comparte y posee una app generativa de imágenes con IA
MyShell AI es una plataforma web para crear, compartir y explorar aplicaciones de IA de generación de imágenes y video, que ayuda a creadores y usuarios en general a realizar ediciones, filtros, retratos, memes y experimentos multimedia. Para diseñadores, especialistas en marketing y creadores de contenido, puede acelerar la conceptualización y la variación de recursos al convertir tareas visuales rutinarias en flujos de trabajo de IA reutilizables.
Midjourney
Midjourney es un laboratorio de investigación financiado por la comunidad que desarrolla modelos de IA para imágenes y video, ayudando a las personas a explorar ideas creativas y nuevos medios visuales, principalmente para artistas, diseñadores y otros profesionales creativos. A medida que los contenidos visuales generados por IA pasan a formar parte de los flujos de trabajo cotidianos, herramientas como Midjourney pueden ayudar a los equipos creativos a prototipar conceptos y comunicar ideas con mayor rapidez.
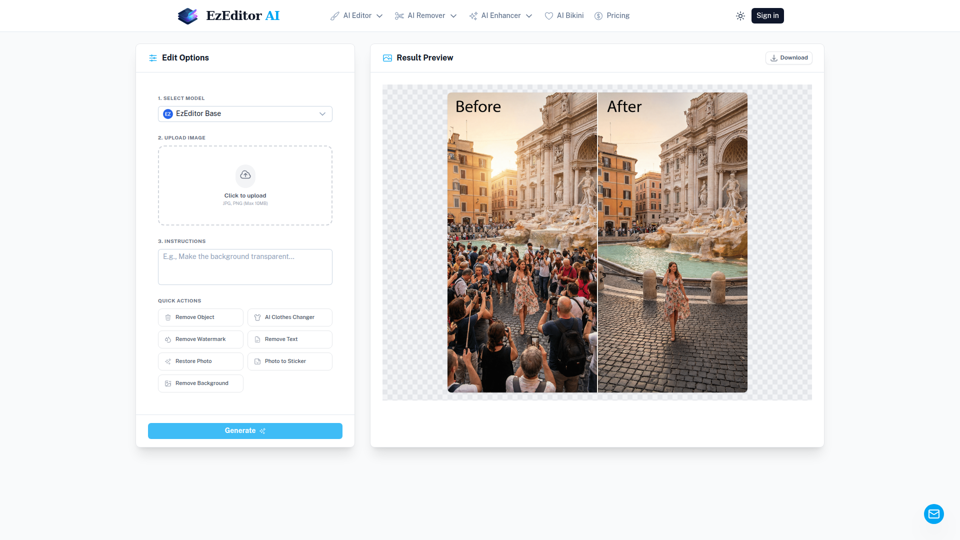
Editor Mágico de IA: Edición de texto a imagen y relleno generativo | EzEditor
EzEditor AI Magic Editor es una herramienta de edición fotográfica con IA basada en navegador que permite a los usuarios editar imágenes mediante instrucciones de texto para tareas como relleno generativo, eliminación de objetos, cambios de ropa y ampliación de imágenes, principalmente para creadores y profesionales del marketing que necesitan ediciones visuales rápidas sin enmascarado manual. En los flujos de trabajo de contenido asistidos por IA, puede ayudar a equipos de redes sociales, diseño y marketing a producir más rápidamente variaciones de imágenes y recursos listos para distintos formatos con menos retoque manual.
Desafíos | Pon a prueba tus habilidades para crear prompts de IA
Prompt Challenge es una plataforma de práctica que ayuda a los usuarios a mejorar la creación de prompts para IA describiendo imágenes y sitios web, comparando los resultados generados por IA con referencias y compitiendo por puntuaciones, principalmente para personas que están aprendiendo ingeniería de prompts y creación práctica con IA. Para diseñadores, desarrolladores y profesionales de la IA, este tipo de prueba repetible de prompts puede perfeccionar las habilidades para redactar instrucciones y mejorar la consistencia al usar herramientas generativas para trabajos visuales y de interfaz.
Descriptorde Imágenes y Video con IA - Modelo de IA Ilimitado - VidGen
VidGen es una plataforma de creación de imágenes y videos con IA que ayuda a los creadores a generar contenido visual, aplicar efectos de IA y explorar múltiples modelos de generación, principalmente para artistas digitales, diseñadores y creadores de contenido profesionales. En los flujos de trabajo creativos impulsados por IA, puede acelerar la ideación y la producción de los equipos visuales al reducir el tiempo necesario para prototipar, animar y perfeccionar conceptos.
VibePaintAI
VibePaintAI es una herramienta de creación de imágenes con IA que ayuda a los usuarios a generar elementos visuales y texto estilizados con apariencias como caricatura, anime, grafiti, cromo, neón, realista y estilos de avatar, principalmente para diseñadores, artistas digitales y creadores de contenido. En los flujos de trabajo creativos asistidos por IA, puede ayudar a los profesionales visuales a explorar rápidamente múltiples direcciones estéticas para gráficos, personajes y arte temático.
Estudio Creativo - Generador de imágenes, videos y modelos 3D con IA | VibeSell.dev
VibeSell Creative Studio es una suite creativa impulsada por IA que ayuda a los creadores a generar imágenes en 4K, videos en HD, modelos 3D, audio, logotipos, mockups y modelos LoRA personalizados, principalmente para diseñadores, especialistas en marketing y vendedores de comercio electrónico. En flujos de trabajo asistidos por IA, puede ayudar a los equipos creativos y de marketing a producir recursos visuales, creatividades publicitarias e imágenes de productos con mayor rapidez, al tiempo que reduce la edición manual en tareas rutinarias de producción.
Generador de imágenes gratuito - Creación de imágenes impulsada por IA
Free Image Generator es una herramienta de creación de imágenes con IA que convierte indicaciones de texto en múltiples imágenes de alta resolución con relaciones de aspecto ajustables y opciones sencillas de imagen a imagen, dirigida principalmente a creadores, especialistas en marketing y personas que necesitan recursos visuales rápidamente sin conocimientos de diseño. En los flujos de trabajo de contenido asistidos por IA, puede ayudar a los equipos de marketing y creatividad a probar conceptos visuales más rápido al generar varias variaciones de imagen a la vez para publicaciones en redes sociales, miniaturas y recursos de campaña.