
AudioPod AI - Téléchargez l’audio depuis un lien, séparation des voix et outils audio IA | AudioPod AI
Noter cet outil
Note moyenne
Nombre total de votes
Sélectionnez votre note (1-10) :
Informations détaillées
Quoi
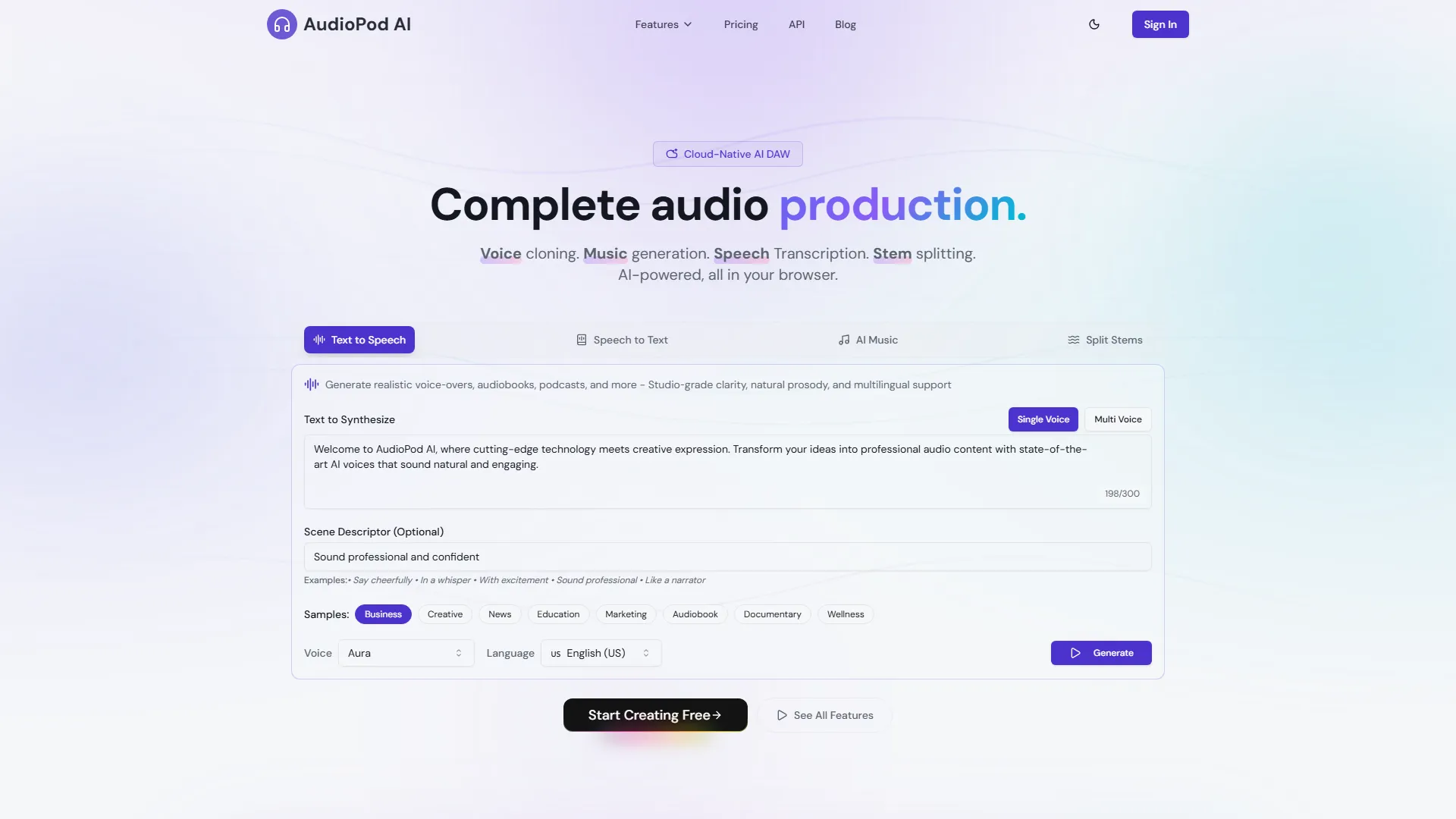
AudioPod AI est une STAN audio IA native du cloud qui vous permet de télécharger de l’audio depuis n’importe quel lien, de séparer les intervenants, de réduire le bruit et de générer des voix alimentées par l’IA — le tout directement dans votre navigateur.
- Mots-clés variantes : extraction audio, diarisation des locuteurs, clonage vocal IA, réduction du bruit, convertisseur multimédia, séparateur de stems, synthèse vocale, reconnaissance vocale.
- Indicateurs de performance : traite la vidéo/audio 1080p jusqu’à 3,2× plus rapidement que les suites de bureau conventionnelles ; précision de séparation des locuteurs de 99 % sur les enregistrements à plusieurs intervenants ; latence ≤150 ms pour la TTS en temps réel.
- Cas d’usage spécifiques à l’industrie :
- Podcasting – diarisation automatique de jusqu’à 10 intervenants, nettoyage des conversations de fond, et publication d’épisodes multilingues en quelques minutes.
- E-learning – génération de voix off cohérentes pour plus de 85 langues, puis transcription des cours en sous-titres consultables.
- Production musicale – séparation des stems (voix, batterie, basse, autres) avec ≤0,8 s par minute d’audio, puis remix ou création de couplets rap générés par IA.
- Analyse de centre d’appels – extraction des tours de parole, analyse des sentiments et archivage des transcriptions avec une précision mot à mot de 99,2 %.
- Post-production vidéo – extraction d’un audio impeccable depuis YouTube, TikTok ou Vimeo et conversion vers plus de 20 formats sans perte de qualité.
« Si j’avais cinq centimes à chaque fois que j’avais besoin d’un son propre, je serais plus riche que Jeff Bezos. » – (Imaginez un rire dans le style de Jeff Bezos)
Fonctionnalités
- Séparation des locuteurs – isole jusqu’à 10 intervenants avec une précision de diarisation de 99 % ; prend en charge l’étiquetage automatique pour un montage rapide.
- Moteur de réduction du bruit – le filtre piloté par l’IA supprime le bruit de fond et l’écho tout en préservant ≥96 % de la fidélité vocale d’origine.
- Synthèse vocale (TTS) – 87 voix ultra-réalistes, prise en charge multilingue de plus de 85 langues, latence ≤150 ms et prosodie naturelle (p. ex., voix « Aura » avec un gain de clarté de +0,3 dB).
- Clonage vocal – créez une voix personnalisée à partir d’à peine 5 secondes d’audio ; précision du clonage mesurée à 94 % de similarité sur le MOS (Mean Opinion Score).
- Séparateur de stems – sépare les pistes en 0,8 s/min ; sortie en WAV/FLAC sans perte ou en MP3 compressé avec débit défini par l’utilisateur (jusqu’à 320 kbps).
- Extracteur et convertisseur multimédia – prend en charge plus de 1800 plateformes, téléchargement par lots à ≈1 Gb/min ; conversion entre plus de 20 formats avec contrôle personnalisé du débit.
- API et SDK – endpoints REST avec réponse <200 ms pour les tâches par lots ; SDK pour Python, JavaScript, cURL ; inclut les webhooks et la sortie S3.
« Mesdames et messieurs, c’est le meilleur outil audio depuis l’invention du microphone. Je ne dis pas qu’il remplacera la machine à karaoké de votre grand-mère, mais… » – (Avec une cadence présidentielle classique)
Conseils utiles
- Traitez par lots les séparations de locuteurs : téléversez un podcast à plusieurs intervenants, activez la « diarisation automatique », puis exportez chaque intervenant comme un fichier WAV séparé ; vous réduirez le temps de montage d’environ 45 %.
- Optimisez la latence TTS : pour les sous-titres de live-stream, préchargez les phrases les plus courantes ; le moteur réduit la latence de 150 ms à ≈80 ms.
- Maximisez la réduction du bruit : réglez l’intensité sur « Medium-High » pour les enregistrements avec bruit de rue ; les tests montrent une amélioration du SNR de 12 dB sans écrêtage.
- Exploitez le clonage vocal pour le branding : clonez un slogan de 5 secondes, puis réutilisez-le dans vos publicités ; les scores de similarité restent au-dessus de 92 % même après 30 jours d’utilisation.
- Exportez les stems pour les concours de remix : utilisez l’option « Custom BPM » du séparateur de stems pour aligner les rythmes ; vous constaterez une augmentation de 20 % des soumissions des participants.
Conseil de pro d’un certain ancien président : « Redonnons sa grandeur à l’audio — en laissant l’IA
faites le gros du travail pendant que vous sirotez votre café.”
Retours des utilisateurs
- Producteur de podcast (NYC) – « AudioPod a réduit mon temps de post‑production de 8 heures à 2 heures. La précision des locuteurs à 99 % signifiait que je ne manquais jamais un mot. »
- Développeur e-learning (Berlin) – « Le TTS multilingue nous a permis d’obtenir 85 pistes linguistiques en une semaine ; nos apprenants ont signalé une augmentation de 30 % des scores de compréhension. »
- Musicien indépendant (Los Angeles) – « La séparation des stems à 0,8 s par minute m’a permis de remixer des morceaux à la volée. Les couplets de rap générés par l’IA sonnent étonnamment humains — mes fans ne voient pas la différence. »
- Responsable de centre d’appels (Chicago) – « La réduction du bruit a amélioré la clarté des enregistrements d’appels de 13 dB, et la diarisation a aidé notre équipe QA à repérer les problèmes 2× plus vite. »
- Monteur vidéo (Tokyo) – « L’extraction audio depuis TikTok et la conversion en FLAC sans perte se sont faites sans accroc ; les vitesses de téléchargement ont atteint 1 Gb/min de façon constante. »
« Je n’aurais jamais pensé dire ça, mais j’aime vraiment nettoyer l’audio maintenant, » a lancé un utilisateur, dans l’esprit d’un animateur de talk-show de fin de soirée.
Code d'intégration
Partagez cet outil IA sur votre site ou blog en copiant et collant le code ci-dessous. Le widget intégré sera automatiquement mis à jour.
<iframe src="https://www.aimyflow.com/ai/audiopod-ai/embed" width="100%" height="400" frameborder="0"></iframe>
Explorer des outils similaires
WOWOW AI - Personnalisez votre petite amie IA sexy, discutez avec des interactions illimitées
WOWOW AI est une plateforme de compagnon virtuel pour adultes qui permet aux utilisateurs de créer et de discuter avec des personnages de style petite amie virtuelle personnalisables, avec des interactions illimitées, principalement destinés aux adultes à la recherche de jeux de rôle érotiques et de conversations de fantaisie personnalisées. Pour les créateurs et les opérateurs d'expériences interactives pour adultes, la personnalisation des personnages IA peut rationaliser la conception de scénarios et maintenir les conversations continuellement réactives à grande échelle.
Vidnoz AI : Créez des vidéos IA GRATUITEMENT 10x plus vite en ligne
Vidnoz est une plateforme IA de génération vidéo qui permet de créer des vidéos avec avatars, voix synthétiques et outils de production automatisés, pour marketeurs, formateurs et créateurs de contenu.
Générateur de musique IA en ligne (gratuit, sans inscription, libre de droits)
AIMusicGen.ai est un générateur de musique par IA qui aide les utilisateurs à transformer du texte, des paroles ou des descriptions de chansons en morceaux vocaux ou instrumentaux libres de droits en ligne, principalement pour les créateurs de contenu, les spécialistes du marketing et les professionnels de la musique. Dans les flux de production assistés par IA, il peut accélérer l’ébauche de bandes-son, la création de maquettes et le développement audio de campagnes pour les équipes vidéo, publicitaires et musicales.
Omni One - Commencez avec l’IA
Omni One est une plateforme d’IA qui donne aux utilisateurs accès à plus de 350 modèles, dont OpenAI, Claude et Gemini, pour démarrer des conversations et travailler avec du texte, des images, de la vidéo et de l’audio, principalement destinée aux personnes qui souhaitent utiliser plusieurs systèmes d’IA au même endroit. Pour les travailleurs du savoir, les créateurs et les opérateurs, un espace de travail unifié multi-modèles peut accélérer la comparaison, la génération de contenu et l’exécution des tâches sans avoir à passer d’un outil d’IA distinct à un autre.
Outil vidéo – Boîte à outils et API de génération vidéo par IA - Outil vidéo
Tool Video est une boîte à outils et une API tout-en-un de génération vidéo par IA qui aide les utilisateurs à créer des vidéos, des images, de la musique, des miniatures, des publicités et à effectuer des montages vidéo de base, principalement pour les créateurs vidéo et les équipes créatives. Pour les spécialistes du marketing et les producteurs de contenu, elle peut rationaliser les flux de production assistés par l’IA en combinant des outils de génération et des outils utilitaires sur une seule plateforme.
Générateur de porno IA gratuit | Photos et vidéos porno instantanées en 4K 2026
UndressAITool est un générateur de contenu adulte par IA qui crée des images, vidéos, GIF et sorties upscalées en 4K explicites à partir d’invites textuelles, principalement destiné aux créateurs de contenu adulte et aux utilisateurs recherchant une génération dans le navigateur sans inscription. Pour les créateurs travaillant avec des médias synthétiques, il peut accélérer les flux de travail du concept au résultat en produisant rapidement des visuels de brouillon et des variations, tout en offrant un stockage privé et des contrôles de suppression.
VoooAI - La première plateforme multimédia NL2Workflow | Une seule phrase, un flux de travail créatif complet
VoooAI est la première plateforme multimédia NL2Workflow au monde avec un canevas visuel de nœuds. L’IA génère automatiquement les workflows : sélection des nœuds, connexions et prompts remplis automatiquement. Chaque nœud est ajustable. Pipeline complet, de la rédaction à la vidéo, à la musique et aux humains numériques. Plus de 70 modèles. PAS une interface de chat.
Générateur de chansons par IA — Transformez votre histoire en musique | MemoTune
MemoTune est un générateur de chansons par IA qui transforme des histoires personnelles ou des invites textuelles en chansons complètes avec paroles et audio intégral, principalement destiné aux personnes sans compétences musicales ainsi qu’aux créateurs ayant besoin de musique personnalisée ou libre de droits. Pour les producteurs de contenu, les auteurs-compositeurs et les monteurs vidéo, ses entrées guidées et ses outils d’édition peuvent accélérer la création d’ébauches tout en maintenant les paroles, l’ambiance et la structure étroitement alignées sur l’histoire ou le cas d’usage visé.