
Berceau
Noter cet outil
Note moyenne
Nombre total de votes
Sélectionnez votre note (1-10) :
Informations détaillées
Quoi
Cradle est une plateforme d’IA pour l’ingénierie des protéines qui aide les équipes de R&D à générer des candidats protéiques, à gérer les cycles expérimentaux et à apprendre des résultats de laboratoire humide au fil du temps. Elle s’adresse aux équipes de biopharma et de biotechnologie industrielle travaillant sur des protéines telles que les anticorps, les enzymes, les vaccins et les peptides.
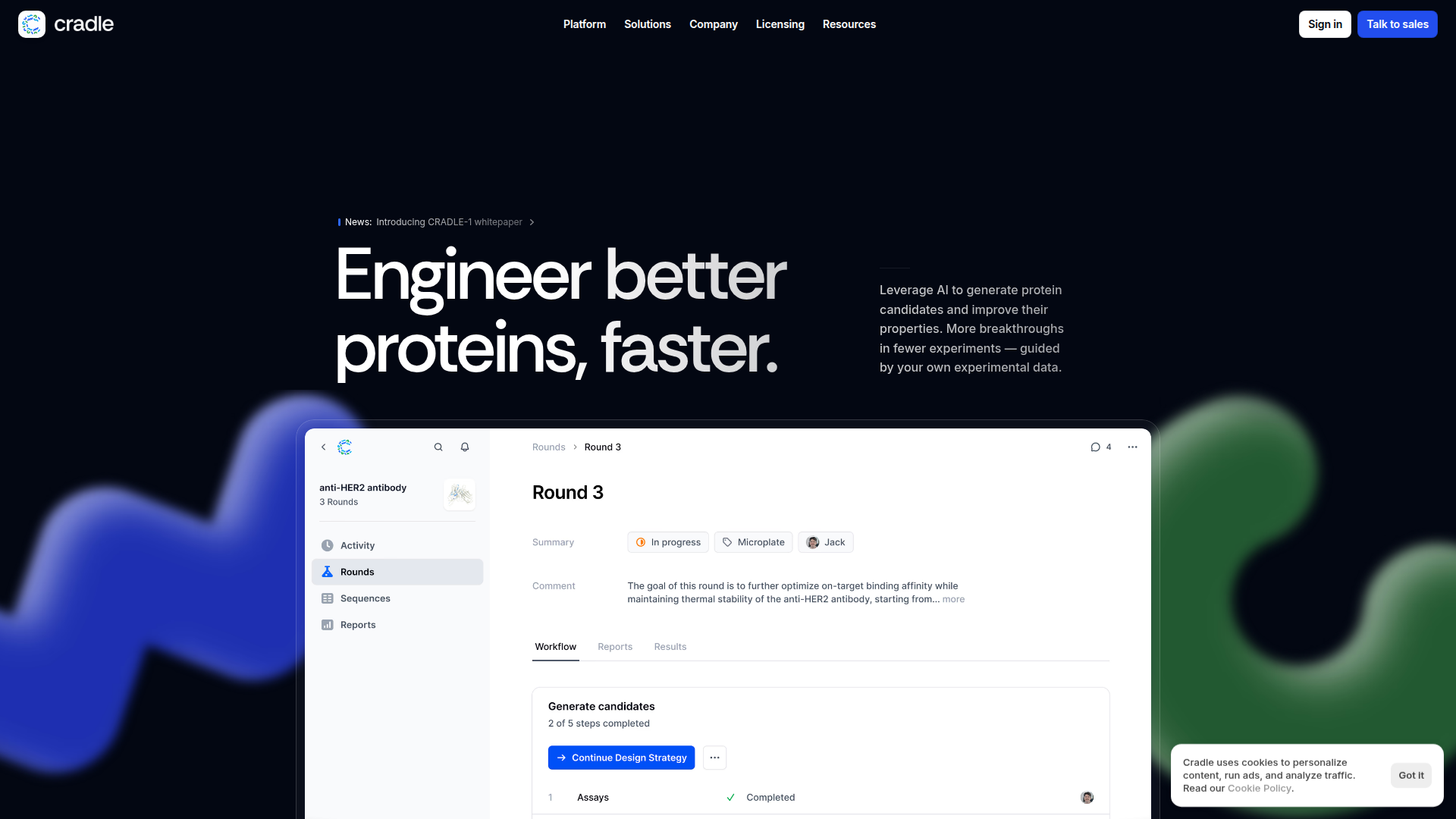
Le flux de travail s’articule autour de l’importation de données expérimentales ou de la définition des objectifs du projet, de l’utilisation de l’IA pour générer des séquences protéiques optimisées selon des contraintes sélectionnées, de l’examen des performances prédites et des mutations dans des rapports, puis de la validation des candidats au laboratoire ou via une CRO. D’après le contenu du site, Cradle est positionnée comme une plateforme logicielle destinée à accélérer l’identification de hits, l’optimisation de leads et, plus largement, les flux de développement de protéines, plutôt que comme un laboratoire de recherche sous contrat.
Fonctionnalités
- Génération guidée par IA de candidats protéiques : Génère des variants protéiques prêts pour le laboratoire en fonction des objectifs du projet, des contraintes et des données expérimentales existantes afin de réduire l’effort manuel de conception de séquences.
- Apprentissage à partir de données itératives de laboratoire humide : Met à jour des modèles personnalisés à mesure que les résultats d’essais sont téléversés, ce qui contribue à améliorer les recommandations au fil des cycles successifs d’optimisation.
- Optimisation multi-propriétés : Permet d’équilibrer des propriétés telles que l’activité, la liaison, la stabilité, la spécificité et l’expression afin que les équipes puissent gérer les compromis dans un seul cycle de conception.
- Rapports de génération et revue de séquences : Fournit des scores de performance prédits, des vues au niveau des plaques et une exploration 3D des mutations pour soutenir la sélection des candidats avant les tests en laboratoire.
- Suivi des cycles et visibilité sur la progression des essais : Permet aux équipes de suivre le statut des cycles et de consulter des métriques en direct par propriété protéique à mesure que les données expérimentales arrivent.
- Confidentialité et infrastructure gérée : Maintient les données clients privées au sein des modèles de l’organisation, avec conformité SOC 2, prise en charge du SSO et infrastructure d’IA entièrement gérée, comme décrit sur la page.
Conseils utiles
- Évaluer tôt la qualité des essais : Pour les produits de cette catégorie, les performances du modèle dépendent fortement de la qualité des données expérimentales ; il est donc important d’examiner tôt la cohérence des essais et la qualité du signal.
- Commencer avec des objectifs d’optimisation clairs : La conception multi-propriétés fonctionne mieux lorsque les équipes définissent dès le départ des priorités et des contraintes mesurables, y compris les compromis acceptables.
- Prévoir une exécution en boucle fermée : La valeur d’une plateforme d’IA pour l’ingénierie des protéines augmente lorsque la conception, les tests et le téléversement des données se déroulent dans un cycle récurrent et rigoureux.
- Examiner l’adéquation opérationnelle au-delà de la qualité du modèle : Le suivi des cycles, les rapports, les contrôles de données et le transfert de séquences vers des laboratoires internes ou des CRO peuvent compter autant que la capacité brute de génération.
- Valider la sécurité et la gestion de la PI pour les programmes sensibles : Pour les projets bio thérapeutiques et industriels, les conditions de confidentialité, de propriété et de contrôle d’accès doivent être examinées avec attention pendant l’évaluation.
Compétences OpenClaw
Cradle pourrait probablement bien s’intégrer à l’écosystème OpenClaw dans le cadre de flux d’orchestration de R&D sur les protéines. Les compétences OpenClaw probables pourraient inclure des agents qui collectent les résultats d’essais depuis les systèmes de laboratoire, normalisent les métadonnées expérimentales, préparent des téléversements structurés pour l’entraînement des modèles, résument les rapports de génération et orientent les candidats sélectionnés vers des flux en aval d’approvisionnement ou de coordination avec des CRO. Le site ne mentionne pas d’intégration native avec OpenClaw ; cela doit donc être considéré comme un schéma d’implémentation probable plutôt que comme une capacité confirmée.
En pratique, cette combinaison pourrait aider les équipes de biologie computationnelle, d’ingénierie des anticorps, de développement enzymatique et de recherche translationnelle en faisant de Cradle une étape au sein d’un système décisionnel semi-automatisé plus large. Les flux OpenClaw probables pourraient inclure un suivi des expériences au niveau du portefeuille, des assistants de revue des candidats, des agents de documentation sensibles à la PI et des copilotes de reporting scientifique reliant les cycles de conception aux jalons du projet. Pour les organisations d’ingénierie des protéines, cela pourrait faire évoluer le travail d’une coordination manuelle fragmentée vers des opérations de développement plus répétables et fondées sur les données.
Code d'intégration
Partagez cet outil IA sur votre site ou blog en copiant et collant le code ci-dessous. Le widget intégré sera automatiquement mis à jour.
<iframe src="https://www.aimyflow.com/ai/cradle-bio/embed" width="100%" height="400" frameborder="0"></iframe>