
Evidently AI - Plateforme d’évaluation de l’IA et d’observabilité des LLM
Noter cet outil
Note moyenne
Nombre total de votes
Sélectionnez votre note (1-10) :
Informations détaillées
Quoi
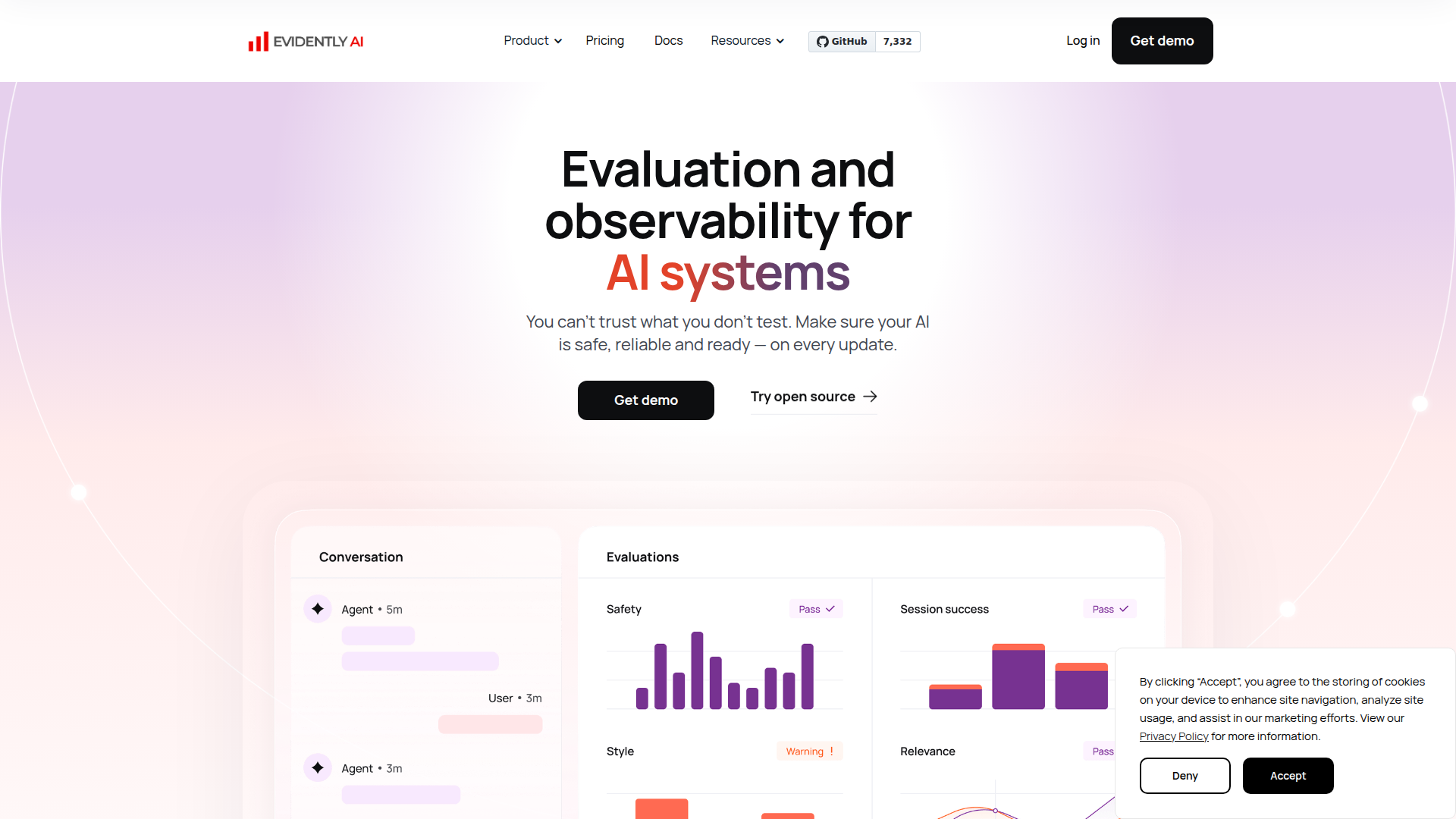
Evidently AI est manifestement une plateforme d’évaluation et d’observabilité de l’IA destinée aux équipes qui développent des applications LLM, des agents IA, des systèmes RAG et des produits de ML traditionnels. Elle est conçue pour aider les équipes IA à tester la qualité, la sécurité, les performances de récupération et le comportement des modèles avant et après les mises à jour.
Le produit semble se positionner à la fois comme une plateforme commerciale et comme un écosystème d’outils centré sur l’open source, construit autour de la bibliothèque Python Evidently. Son flux de travail principal couvre la génération de cas de test, l’exécution d’évaluations automatisées avec des métriques intégrées ou personnalisées, ainsi que le suivi continu des performances au moyen de tableaux de bord et de rapports afin de détecter les régressions, la dérive et les risques émergents.
Fonctionnalités
- Évaluation automatisée de l’IA — Mesure l’exactitude, la sécurité et la qualité des sorties, puis met en évidence les points de défaillance au niveau des réponses dans des rapports partageables.
- Génération de tests synthétiques et adversariaux — Crée des entrées réalistes de type cas limite et attaque, adaptées à un cas d’usage spécifique, ce qui aide les équipes à sonder les modes de défaillance avant le déploiement.
- Tests continus et observabilité — Suit le comportement du système à travers les mises à jour de modèles ou de prompts afin que les équipes puissent détecter la dérive, les régressions et de nouveaux risques au fil du temps.
- Plus de 100 métriques intégrées avec prise en charge d’évaluations personnalisées — Permet aux équipes de combiner des règles, des classificateurs et des juges basés sur des LLM pour définir un système de qualité adapté à leur application.
- Évaluation spécifique au RAG — Teste la qualité de la récupération, la pertinence du contexte et le comportement halluciné afin d’améliorer les réponses fondées dans les systèmes basés sur la récupération.
- Tests des agents IA et des systèmes prédictifs — Étend l’évaluation au-delà des sorties d’un seul LLM aux workflows en plusieurs étapes, à l’utilisation d’outils, aux classificateurs, aux résumeurs, aux systèmes de recommandation et à d’autres modèles de ML.
Conseils utiles
- Définissez d’abord les critères d’évaluation par mode de défaillance — Pour des produits comme celui-ci, il est généralement plus efficace d’organiser les tests autour des hallucinations, des fuites de données personnelles, des sorties dangereuses et des ruptures de workflow qu’autour de scores de modèle génériques.
- Utilisez à la fois l’évaluation hors ligne et l’évaluation continue — Les tests avant mise en production permettent de repérer les problèmes évidents, mais la valeur de la plateforme est maximale lorsque les équipes surveillent aussi les changements après le déploiement.
- Adaptez les métriques au contexte métier — Les métriques intégrées sont de bons points de départ, mais des règles spécifiques au domaine et des vérifications fondées sur des prompts sont souvent nécessaires pour définir des critères d’acceptation pertinents.
- Priorisez les workflows à haut risque pour les tests d’agents — Les systèmes en plusieurs étapes peuvent échouer par effet de cascade, commencez donc par les tâches impliquant des appels d’outils, des données sensibles ou une automatisation orientée client.
- Validez la récupération séparément de la génération — Dans les systèmes RAG, il est utile d’isoler la pertinence du contexte et la qualité de la récupération avant d’attribuer de mauvais résultats uniquement au LLM.
Compétences OpenClaw
Evidently AI pourrait probablement compléter OpenClaw en fournissant des couches d’évaluation, de supervision et de tests de régression pour les workflows IA construits au sein d’un écosystème d’agents plus large. Un cas d’usage probable serait des agents OpenClaw qui exécutent automatiquement des suites de benchmarks sur des prompts, des chaînes RAG ou des tâches d’agents après chaque mise à jour de modèle, de politique ou de workflow, puis résument les échecs par catégorie, comme les hallucinations, les sorties dangereuses ou les écarts de récupération.
Un autre usage probable concernerait les compétences OpenClaw axées sur les opérations de gouvernance de l’IA : génération d’ensembles de tests adversariaux, examen de tableaux de bord de dérive, routage des incidents et recommandation d’étapes de remédiation pour les prompt engineers, les ingénieurs ML ou les responsables produit. Bien combiné, cet ensemble pourrait aider les équipes IA à passer de tests ponctuels à des opérations d’évaluation répétables, en particulier dans les environnements où les applications LLM et les systèmes de ML sont fréquemment mis à jour.
Code d'intégration
Partagez cet outil IA sur votre site ou blog en copiant et collant le code ci-dessous. Le widget intégré sera automatiquement mis à jour.
<iframe src="https://www.aimyflow.com/ai/evidentlyai-com/embed" width="100%" height="400" frameborder="0"></iframe>
Explorer des outils similaires
Éditeur photo IA gratuit : modifier et générer des images en ligne | Pokecut
Pokecut est un éditeur photo IA qui permet de supprimer l’arrière-plan, améliorer des images et générer des visuels en ligne, surtout pour les vendeurs e-commerce, marketeurs et créateurs. Il accélère la production d’images pour créer des contenus prêts à l’emploi avec moins de retouches manuelles.
Qoder - La plateforme de développement agentique
Qoder est une plateforme de développement agentique qui aide les développeurs à comprendre les bases de code et exécuter des tâches logicielles avec des agents IA, surtout pour les ingénieurs logiciel et équipes de développement. Elle améliore la productivité grâce à un fort contexte code et des modèles avancés.
Seedance 2.0
Seedance 2.0 est le modèle de génération vidéo par IA de ByteDance, conçu pour créer des vidéos de haute qualité à partir de prompts et d’entrées multimodales, surtout pour les créateurs, développeurs et équipes média. À l’ère de l’IA, il aide les équipes visuelles à transformer des idées en vidéos prêtes à produire avec bien moins de montage manuel.
Struct | Automatisez votre runbook d’astreinte
Struct est un agent IA d’astreinte qui enquête sur les alertes d’ingénierie et bugs en analysant logs, métriques, traces et bases de code, surtout pour les ingénieurs logiciels et équipes SRE. À l’ère de l’IA, il aide à réduire le temps de triage en livrant directement dans les workflows des causes racines et correctifs suggérés.
Handit.ai — Le moteur open source qui améliore automatiquement vos agents IA
Handit.ai est un moteur d’optimisation open source qui évalue les décisions des agents IA, génère de meilleurs prompts et jeux de données, et teste les changements en A/B pour les équipes qui créent et exploitent des agents IA.
Correcteur grammatical IA gratuit - LanguageTool
LanguageTool est un assistant d’écriture et de grammaire basé sur l’IA qui aide à vérifier grammaire, orthographe, ponctuation et style dans plus de 30 langues.
Trace
Trace est un logiciel conçu pour améliorer les workflows numériques en aidant les équipes à organiser, suivre ou analyser leur travail plus efficacement.
L’IA pour les résolveurs de problèmes | Claude par Anthropic
Claude d’Anthropic est un assistant IA conçu pour les personnes qui résolvent des problèmes. Il aide les utilisateurs à mener à bien des tâches complexes telles que la rédaction, le codage, l’analyse de données, la recherche et l’organisation des tâches, principalement pour les professionnels, les développeurs et les équipes travaillant sur des projets difficiles. Dans les flux de travail assistés par l’IA, il peut aider les travailleurs du savoir et les équipes logicielles à passer plus rapidement de l’analyse à l’exécution tout en laissant aux personnes le contrôle des validations et de l’accès aux fichiers.