
JURA Bio, Inc.
このツールを評価
平均スコア
総投票数
スコアを選択(1〜10):
詳細情報
概要
JURA Bioは、治療薬設計向けの基盤モデルを構築し、それをウェットラボ実験と組み合わせています。その中核的なアプローチはクローズドなデータループです。すなわち、モデルがラボでの設計・合成・スクリーニングを導き、そこで得られた機能データを用いて、時間をかけてモデルを継続的に改善していきます。
同社は、新規治療モダリティや難易度の高い標的に取り組むバイオテック企業や創薬組織を主な対象としているようです。こうした領域では公開データセットが限られ、汎用的なAIツールの有効性も低くなりがちです。ページの内容からは、JURAは独自モデル開発と候補探索・初期開発を組み合わせた、AIネイティブな治療薬探索プラットフォームとして位置付けられています。
特徴
- 独立型AIモデル: 目的特化型の基盤モデルは独自の機能データで学習されており、公開データが存在しない、あるいは不十分な探索業務を支援することを意図しています。
- ラボ主導の学習ループ: モデルがウェットラボ実験の方向付けを行い、設計・合成・スクリーニングの各サイクルで新たなデータが生成され、それによってモデル性能が洗練されます。
- 難標的および新規モダリティへの対応: このプラットフォームは、既製のAIアプローチでは対応が難しい治療領域に有用であると提示されています。
- 候補探索と開発: JURAは、in silico設計のみにとどまらず、機能が確認された治療候補の探索と開発を行うとしています。
- 複数の治療フォーマットをカバー: 同社は、抗体、TCRミミック、ペプチド、T細胞エンゲージャー、酵素、および新興モダリティを適用領域として挙げています。
- 提携志向のモデル活用: 公開されている提携事例から、このプラットフォームはバイオ医薬品開発、制御エレメント設計、免疫細胞関連の治療プログラムに適用可能であることが示唆されます。
参考ポイント
- この種の製品では、主張される優位性のどの程度が独自の実験データ生成に由来し、どの程度がモデルアーキテクチャに由来するのかを見極めてください。というのも、元情報では技術的なモデル詳細よりもデータループが強調されているためです。
- デューデリジェンスや導入計画では、このプラットフォームがワークフローのどこに位置するのかを確認してください。たとえば、標的選定、配列設計、スクリーニング最適化、候補優先順位付け、あるいはより広範な前臨床開発のどこを担うのか、という点です。
- モダリティ適合性は慎重に評価してください。ページでは複数の治療クラスが挙げられていますが、それらすべてで能力が同程度に成熟しているかどうかは説明されていません。
- 提携スキームとIPに関する期待値は早い段階で確認してください。特に、独自データの創出と、反復的な実験サイクルを通じたモデル改善を基盤とするプラットフォームでは重要です。
- 機能確認済みという主張は有望ではあるものの、このページにはプログラム別の検証データが示されていないため、そのようなデータが伴わない限り初期段階のものとして扱うべきです。
OpenClawスキル
OpenClawエコシステムにおいて、JURA Bioはマルチエージェント型のR&Dワークフロー内で、科学的な設計・意思決定エンジンとして最も適している可能性があります。想定されるユースケースとしては、プログラム目標を実験ブリーフへ変換するエージェント、設計サイクルを要約するエージェント、モダリティ横断で候補クラスを比較するエージェント、スクリーニング結果を追跡するエージェント、提携先向けの研究アップデートを準備するエージェントなどが含まれます。元ページにはOpenClawとのネイティブ統合についての記載はないため、これは確認済みの製品機能ではなく、ワークフロー上の推論として読むべきです。
OpenClawを組み合わせた構成は、特にバイオテックの研究チーム、アライアンスマネージャー、トランスレーショナル戦略グループにとって有用である可能性があります。たとえば、あるエージェントが標的仮説を整理し、別のエージェントがウェットラボ結果の解釈を構造化し、さらに別のエージェントがモダリティ別の設計判断や提携から得られた知見のリビングナレッジベースを維持するといった形です。実務上、そのようなレイヤーは、JURAのようなプラットフォームを単なる専門的な探索エンジンから、AIネイティブな治療薬R&Dのためのより広範なオペレーティングシステムの一部へと発展させる助けになる可能性があります。
埋め込みコード
以下のコードをコピーしてサイトやブログに貼り付けると、この AI ツールを掲載できます。埋め込みウィジェットは最新情報に自動更新されます。
<iframe src="https://www.aimyflow.com/ai/jura-bio/embed" width="100%" height="400" frameborder="0"></iframe>
類似ツールを探す
プロフルエント
Profluent は、医療、農業、産業用酵素の分野における応用に向けて、生物学チームが新しいタンパク質や遺伝子編集ツールを設計できるよう支援する AI タンパク質設計プラットフォームです。分子生物学者、バイオエンジニア、創薬チームにとって、AI が設計したタンパク質は、天然の足場を超える新規の治療候補や遺伝子編集候補の探索を加速できます。
HELIOPOLIS BIOTECH - タンパク質設計、抗体設計
Heliopolis Biotechは、計算アルゴリズムと実験的特性評価を活用して、バイオテクノロジーおよび創薬チームによる新規治療用タンパク質、バインダー、再設計タンパク質の開発を支援する、タンパク質および抗体設計企業です。AI主導の治療薬研究開発において、この種のプラットフォームは、タンパク質エンジニアや創薬研究者が分子設計から前臨床候補の評価へ、より迅速に進むことを支援できます。

ProteinQure
ProteinQureは、主に精密医療を開発する創薬チームおよびバイオ医薬品パートナー向けに、AI駆動型のProteinStudioプラットフォームを用いて新規のペプチドベース治療薬および組織特異的デリバリーシステムを設計する、臨床段階のバイオテクノロジー企業です。腫瘍学およびトランスレーショナルリサーチの専門家にとって、その計算論的ペプチド設計アプローチは、より精密なペイロード送達を備えた標的治療の開発加速に役立ちます。
Menten AI
Menten AI は、ペプチドマクロサイクル創薬設計のための生成AIプラットフォームであり、主に製薬および創薬研究者向けに、複雑な標的に対するペプチドの設計と最適化を支援します。医薬品化学者や計算生物学チームにとっては、生成モデルを物理ベースおよび量子シミュレーションと組み合わせることで、前臨床候補の探索を加速できます。
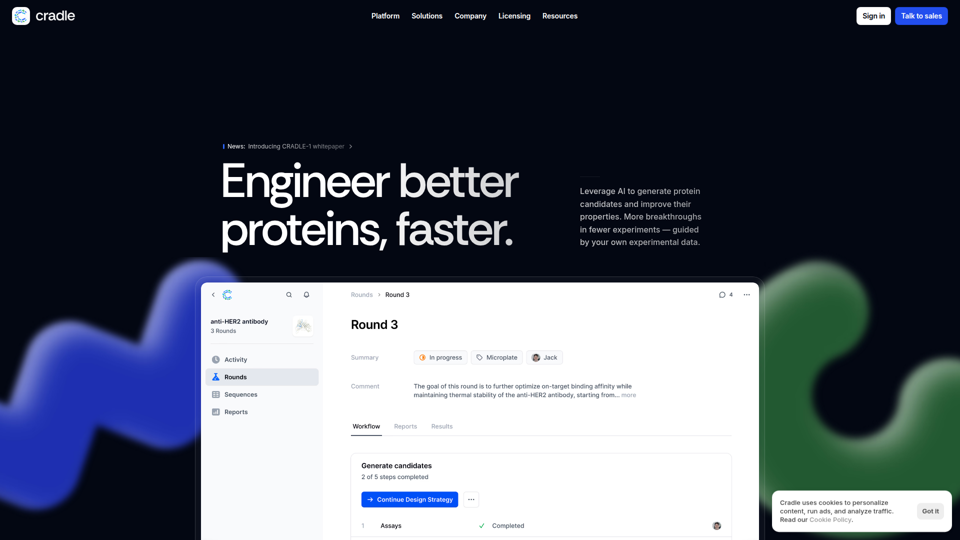
揺りかご
Cradle は、バイオ医薬および産業バイオの R&D チームが自社の実験データを用いてタンパク質候補を生成・最適化できるよう支援する、タンパク質工学向けの AI プラットフォームです。タンパク質エンジニアや R&D 科学者にとって、各アッセイラウンドから学習することで、より少ない実験でより迅速な多特性最適化を支援し、設計・構築・試験のサイクルを短縮できます。
Antiverse:困難な標的に対する抗体の設計
Antiverseは、治療薬開発における困難な標的に対する抗体設計を、創薬チームが進められるよう支援することに特化した、機械学習駆動型の抗体設計プラットフォームです。AIを活用したバイオ医薬品の研究開発において、これは抗体探索の研究者や計算生物学チームが、対応の難しい標的に取り組む際に候補をより効率的に優先順位付けするのに役立ちます。

生成:Biomedicines | ホーム
Generate:Biomedicinesは、Generate Platformを通じて機械学習、生物工学、医療を活用し、主に創薬およびバイオ医薬品チーム向けに新規のタンパク質ベース医薬品を設計・開発する治療薬企業です。研究者や治療法開発者にとって、このAI主導の生成生物学アプローチは、設計・検証サイクルを短縮し、医薬品開発におけるより標的を絞ったタンパク質工学を支援します。
10x Science:科学者向けのAIネイティブソフトウェア
10x Scienceは、科学者向けのAIネイティブなソフトウェアで、タンパク質の特性解析やオミクスデータの大規模解析を支援します。ペプチドマッピング、de novoシーケンシング、PTM検出、プロテオフォーム解析の機能を備え、特にタンパク質治療薬のワークフローに適しています。タンパク質科学者や分析チームにとって、複雑な質量分析データの解釈を迅速化し、従来のツールでは見逃される可能性のある配列バリアントや修飾の発見に役立ちます。