
Evidently AI - AI Evaluation & LLM Observability Platform
Rate this Tool
Average Score
Total Votes
Select your score (1-10):
Detail Information
What
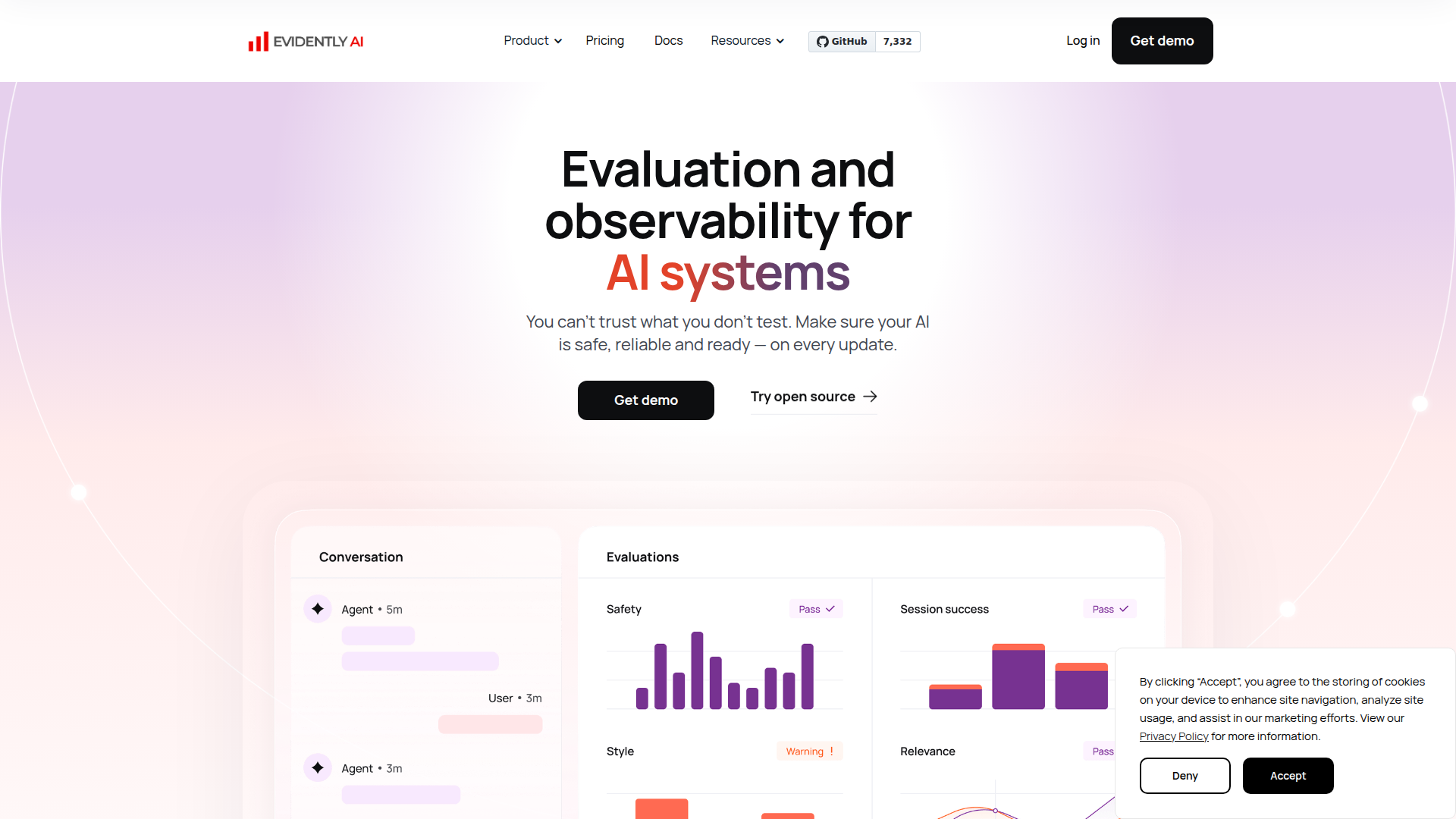
Evidently AI is an AI evaluation and observability platform for teams building LLM applications, AI agents, RAG systems, and traditional ML products. It is designed to help AI builders test quality, safety, retrieval performance, and model behavior before and after updates.
The product appears positioned as both a commercial platform and an open-source-centered tooling ecosystem, built on the Evidently Python library. Its core workflow covers generating test cases, running automated evaluations with built-in or custom metrics, and continuously tracking performance through dashboards and reports to catch regressions, drift, and emerging risks.
Features
- Automated AI evaluation — Measures output accuracy, safety, and quality, then surfaces failure points at the response level in shareable reports.
- Synthetic and adversarial test generation — Creates realistic edge-case and attack-style inputs tailored to a specific use case, which helps teams probe failure modes before deployment.
- Continuous testing and observability — Tracks system behavior across model or prompt updates so teams can detect drift, regressions, and new risks over time.
- 100+ built-in metrics with custom evaluation support — Lets teams combine rules, classifiers, and LLM-based judges to define a quality system that fits their application.
- RAG-specific evaluation — Tests retrieval quality, context relevance, and hallucination behavior to improve grounded responses in retrieval-based systems.
- AI agent and predictive system testing — Extends evaluation beyond single LLM outputs to multi-step workflows, tool use, classifiers, summarizers, recommenders, and other ML models.
Helpful Tips
- Define evaluation criteria by failure mode first — For products like this, it is usually more effective to organize tests around hallucinations, PII leakage, unsafe outputs, and workflow breakdowns than around generic model scores.
- Use both offline and continuous evaluation — Pre-release testing catches obvious issues, but the platform’s value is strongest when teams also monitor changes after deployment.
- Customize metrics to the business context — Built-in metrics are useful starting points, but domain-specific rules and prompt-based checks are often necessary for meaningful acceptance criteria.
- Prioritize high-risk workflows for agent testing — Multi-step systems can fail through cascading errors, so start with tasks that involve tool calls, sensitive data, or customer-facing automation.
- Validate retrieval separately from generation — In RAG systems, it helps to isolate context relevance and retrieval quality before attributing poor outcomes only to the LLM.
OpenClaw Skills
Evidently AI could likely complement OpenClaw by supplying evaluation, monitoring, and regression-testing layers for AI workflows built inside a broader agent ecosystem. A likely use case would be OpenClaw agents that automatically run benchmark suites on prompts, RAG chains, or agent tasks after every model, policy, or workflow update, then summarize failures by category such as hallucination, unsafe output, or retrieval mismatch.
Another likely fit is for OpenClaw skills focused on AI governance operations: generating adversarial test sets, reviewing drift dashboards, routing incidents, and recommending remediation steps for prompt engineers, ML engineers, or product owners. If combined well, this pairing could help AI teams move from ad hoc testing to repeatable evaluation operations, especially in environments where LLM apps and ML systems are updated frequently.
Embed Code
Share this AI tool on your website or blog by copying and pasting the code below. The embedded widget will automatically update with the latest information.
<iframe src="https://www.aimyflow.com/ai/evidentlyai-com/embed" width="100%" height="400" frameborder="0"></iframe>
Explore Similar Tools
Free AI Photo Editor: Edit & Generate Image Online | Pokecut
Pokecut is an AI photo editor that helps users remove backgrounds, enhance images, and generate visuals online, mainly for ecommerce sellers, marketers, and creators who need quick design-ready assets. It speeds up routine image production so visual teams can create polished content with less manual editing.
Qoder - The Agentic Coding Platform
Qoder is an agentic coding platform that helps developers understand codebases and execute software tasks with AI agents, mainly for professional software engineers and development teams. It improves engineering throughput by combining strong code context with advanced models for more reliable task completion.
Seedance 2.0
Seedance 2.0 is ByteDance's AI video generation model designed to create high-quality videos from prompts and multimodal inputs, mainly for creators, developers, and media teams. In the AI era, it helps visual content roles turn ideas into production-ready motion assets with far less manual editing effort.
Struct | Automate your on-call runbook
Struct is an AI on-call agent that investigates engineering alerts and bugs by analyzing logs, metrics, traces, and codebases, mainly for software engineers and SRE teams. In the AI era, it helps incident responders shorten triage time by delivering root-cause findings and suggested fixes directly in workflows.
Handit.ai — The Open Source Engine that Auto-Improves Your AI Agents
Handit.ai is an open-source optimization engine that evaluates AI agent decisions, generates improved prompts and datasets, and A/B tests changes for teams building and operating AI agents. It helps AI engineers and product teams improve agent quality faster while keeping tighter control over production behavior.
Free AI Grammar Checker - LanguageTool
LanguageTool is an AI-powered grammar and writing assistant that helps users check grammar, spelling, punctuation, and style across more than 30 languages, mainly for students, professionals, and multilingual teams. It helps writing-heavy roles communicate more clearly and edit faster at scale.
Trace
Trace is a software tool designed to support digital workflows, likely focused on helping teams organize, monitor, or analyze work more effectively. In the AI era, tools that centralize operational visibility help technical and business roles make faster decisions with less manual follow-up.
The AI for Problem Solvers | Claude by Anthropic
Claude by Anthropic is an AI assistant for problem solvers that helps users tackle complex work such as writing, coding, data analysis, research, and organizing tasks, mainly for professionals, developers, and teams handling difficult projects. In AI-enabled workflows, it can help knowledge workers and software teams move faster from analysis to execution while keeping people in control of approvals and file access.