
Home | Deasy Labs
Rate this Tool
Average Score
Total Votes
Select your score (1-10):
Detail Information
What
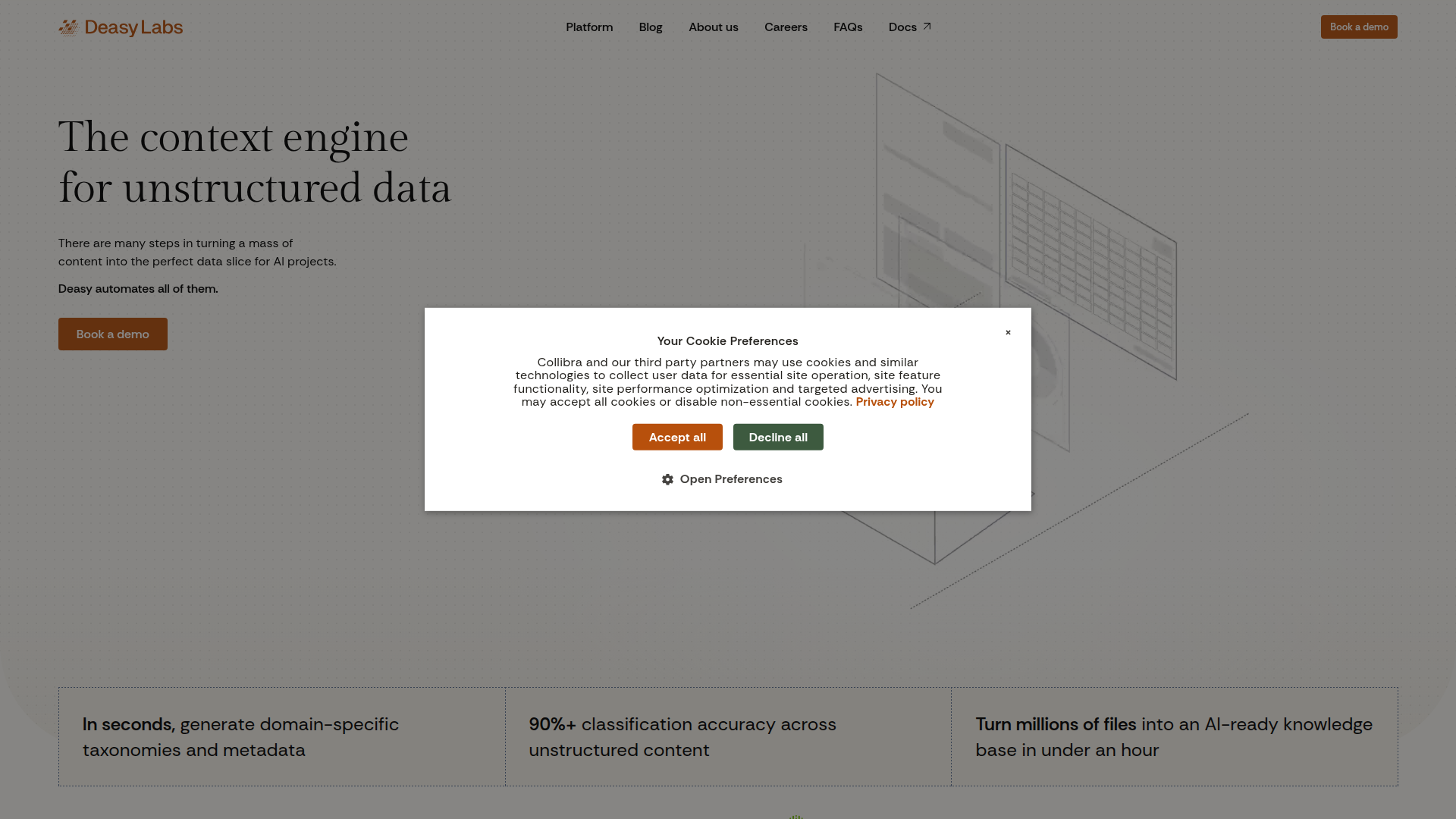
Deasy Labs is a platform for turning unstructured content into AI-ready knowledge bases. It automates content discovery, tagging, filtering, enrichment, deduplication, quality control, and sensitive-data classification so teams can produce usable data slices for AI systems without building and maintaining custom pipelines.
The product appears designed for organizations building AI, retrieval, or agentic systems that depend on large volumes of internal documents and other unstructured files. Its positioning is best understood as a context engine or data-preparation layer for enterprise AI workflows, with an emphasis on fast taxonomy generation, metadata creation, and ongoing maintenance to prevent knowledge decay as source content changes.
Features
- Automated content discovery and tagging: Finds relevant unstructured content and applies metadata so teams can organize and retrieve the right material more efficiently.
- Domain-specific taxonomy generation: Generates taxonomies from the source data itself, which helps reduce manual subject-matter-expert effort during knowledge-base setup.
- Filtering, deduplication, and enrichment: Removes irrelevant or duplicated content and adds semantic context to improve downstream AI retrieval quality.
- Sensitive-data classification: Identifies sensitive content so it can be excluded from the data slice before it reaches an AI model.
- Continuous knowledge-base maintenance: Updates metadata and data products over time as content changes, helping reduce drift and stale knowledge in AI systems.
- Scalable AI-ready data preparation: Supports turning very large file collections into structured knowledge bases quickly; the homepage claims this can be done for millions of files in under an hour.
Helpful Tips
- Evaluate this kind of platform against a representative sample of your own unstructured data, because taxonomy quality and retrieval value depend heavily on domain complexity and document variation.
- Confirm how sensitive-data handling fits your governance process; the site states classification and filtering, but does not provide detailed implementation or policy controls on the homepage.
- Test ongoing maintenance workflows, not just initial ingestion, since Deasy’s differentiation appears tied to preventing knowledge decay as documents and labels evolve.
- For RAG or agentic use cases, measure whether the generated metadata improves retrieval precision and context quality versus a simpler keyword or vector-only baseline.
- If your team currently relies on manual data preparation or custom pipelines, compare operational effort over time, especially around taxonomy updates, deduplication, and relevance filtering.
OpenClaw Skills
Within an OpenClaw ecosystem, Deasy Labs would likely fit upstream of retrieval, reasoning, and workflow agents as the system that prepares and maintains the knowledge layer those agents depend on. Likely use cases include OpenClaw skills for document intake, policy-aware dataset curation, knowledge-base refresh monitoring, and domain-specific metadata routing for agents that answer questions, summarize records, or support internal research.
That combination could be especially useful in industries with large, messy document estates such as healthcare, legal, enterprise knowledge management, and regulated operations. A likely OpenClaw workflow could use Deasy to classify, enrich, and filter source files, then pass curated slices into agents for RAG, case support, or decision-assistance workflows. The homepage does not confirm a native OpenClaw integration, so this should be treated as a plausible architecture pattern rather than a documented product capability.
Embed Code
Share this AI tool on your website or blog by copying and pasting the code below. The embedded widget will automatically update with the latest information.
<iframe src="https://www.aimyflow.com/ai/deasylabs-com/embed" width="100%" height="400" frameborder="0"></iframe>
Explore Similar Tools
Bright Data for AI – Connect Your AI to the Web
Bright Data for AI is a web data platform that helps AI teams search, crawl, extract, and collect structured real-time and training data from the web through APIs, remote browsers, datasets, and automation tools. For AI engineers, data scientists, and agent builders, it can reduce the effort of building web access and data acquisition pipelines so they can focus more on model behavior and application logic.
Autonomous AI for Data Teams | Databricks
Databricks Genie Code is an autonomous AI tool in the Databricks workspace that helps data teams plan, execute, and maintain data science, machine learning, data engineering, analytics, and dashboard workflows using natural language and enterprise data context. For data engineers, data scientists, and analysts, it can reduce manual orchestration by grounding work in governed metadata and proactively supporting production pipelines, models, and BI assets.
BlazorData - Home
BlazorData is a Blazor-based data orchestration platform for enterprise-grade data management, transformation, and workflow automation, mainly aimed at teams handling structured data processes in business or technical environments. In AI-era workflows, it can help data and operations professionals organize cleaner, more reliable pipelines that support automation and downstream analysis.
Blackshark.ai - AI Infrastructure for the Physical World
Blackshark.ai is an AI geospatial infrastructure platform that turns satellite, aerial, drone, and sensor imagery into structured world models and simulation-ready 3D environments for government and enterprise teams working with large-scale physical-world data. For geospatial analysts, disaster response planners, and simulation teams, it can speed change detection, situational awareness, and AI training by converting massive imagery streams into operational intelligence.
Generate SQL Queries in Seconds for Free - SQLAI.ai
SQLAI.ai is an AI SQL assistant that helps analysts, data engineers, developers, and data teams generate, optimize, validate, format, explain, and run SQL or NoSQL queries from natural language across many database engines. For analytics and engineering work, it can shorten query drafting and review cycles by combining schema-aware generation with validation and readable explanations.
Sentiment Analysis with MindsDB and OpenAI using SQL - MindsDB
This MindsDB tutorial shows developers how to use SQL to create an OpenAI-powered sentiment analysis model inside a database and classify text reviews as positive, neutral, or negative. For data engineers and application developers, this approach can speed up adding AI text analysis to database workflows without building a separate machine learning pipeline.

OSSUS
OSSUS is a self-healing data infrastructure platform that helps organizations turn fragmented records into trusted, agent-ready systems of truth, mainly for teams responsible for data and AI foundations. As AI adoption grows, it can help data, analytics, and engineering professionals improve reliability by giving AI systems cleaner, more dependable information to work from.
Unsiloed AI
Unsiloed AI is a document processing platform that turns multimodal unstructured data like PDFs, spreadsheets, slides, and images into structured JSON or Markdown for LLMs, AI agents, and automation, mainly for developers, AI engineers, and data teams in accuracy-critical enterprises. In AI workflows, it can help data engineering, ML, and operations teams reduce manual parsing work and improve retrieval quality by preserving document structure, hierarchy, and domain context.